Computer Vision Platform
A unified no-code machine learning platform for training image classification, object detection, and regression models.
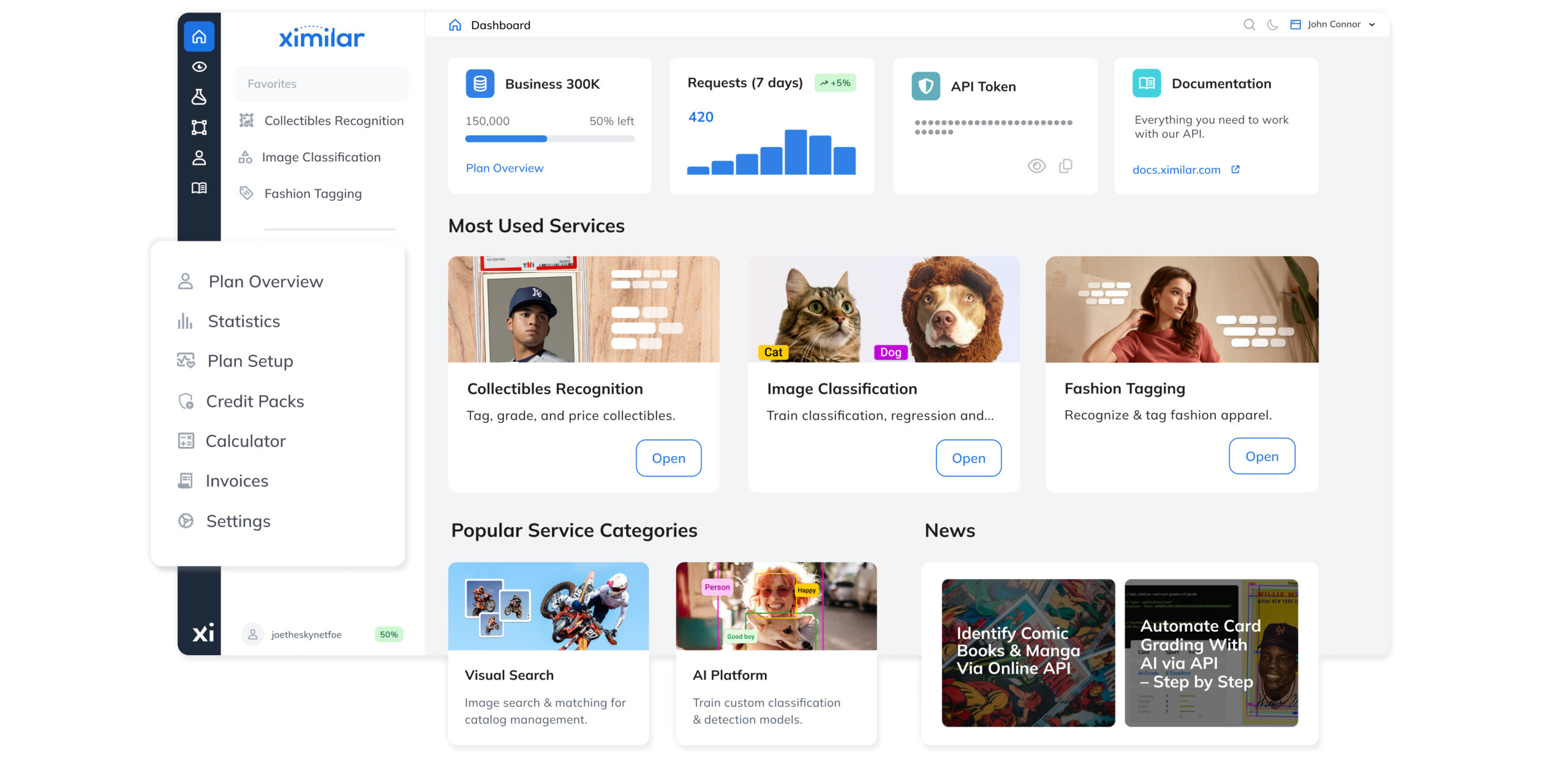
Image Classification
Models for automatic recognition, categorization & tagging of images or objects in them.
CATEGORIZE & TAG
Train Your Own Visual AI
Define your own categories & tags, link them to training images, and build & deploy custom image recognition models – no coding required. The system handles the underlying compute so you can focus on your data and workflow.
Automate all image categorization: sorting, tagging, filtering, quality control, and security checks. Whether you are a startup processing thousands of product images or an enterprise running high-volume, real-time pipelines, the system scales to your workload.
AUTOMATE ROUTINE TASKS
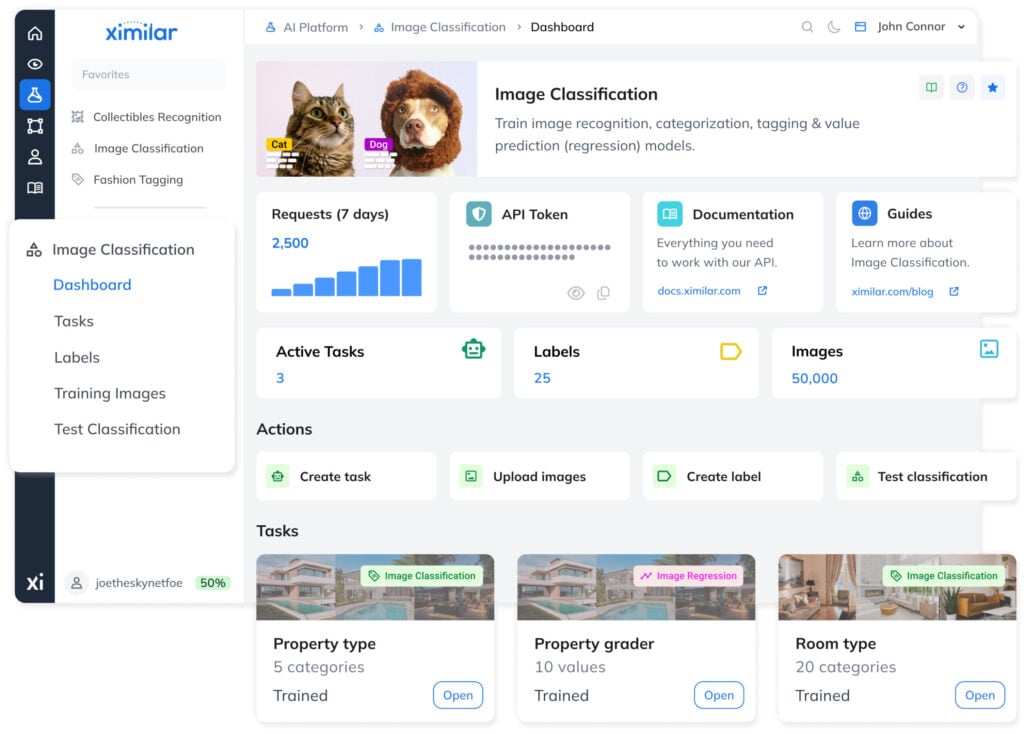
No-Code Machine Learning
Working with Ximilar requires no programming experience. You train and chain your models with a few clicks, using an intuitive interface that is accessible to both newbies and data scientists alike.
Ximilar runs on cloud infrastructure, processing large volumes of data 24/7. Connect via REST and integrate both ready-to-use and custom models into your existing systems – using direct HTTP calls or the available SDKs that accelerate integration further.

Enrich
your data with detailed information

Delegate
routine tasks to consistent AI

Save
time and resources with AI automation
WHAT IS CATEGORIZATION?
Assign a category to each image
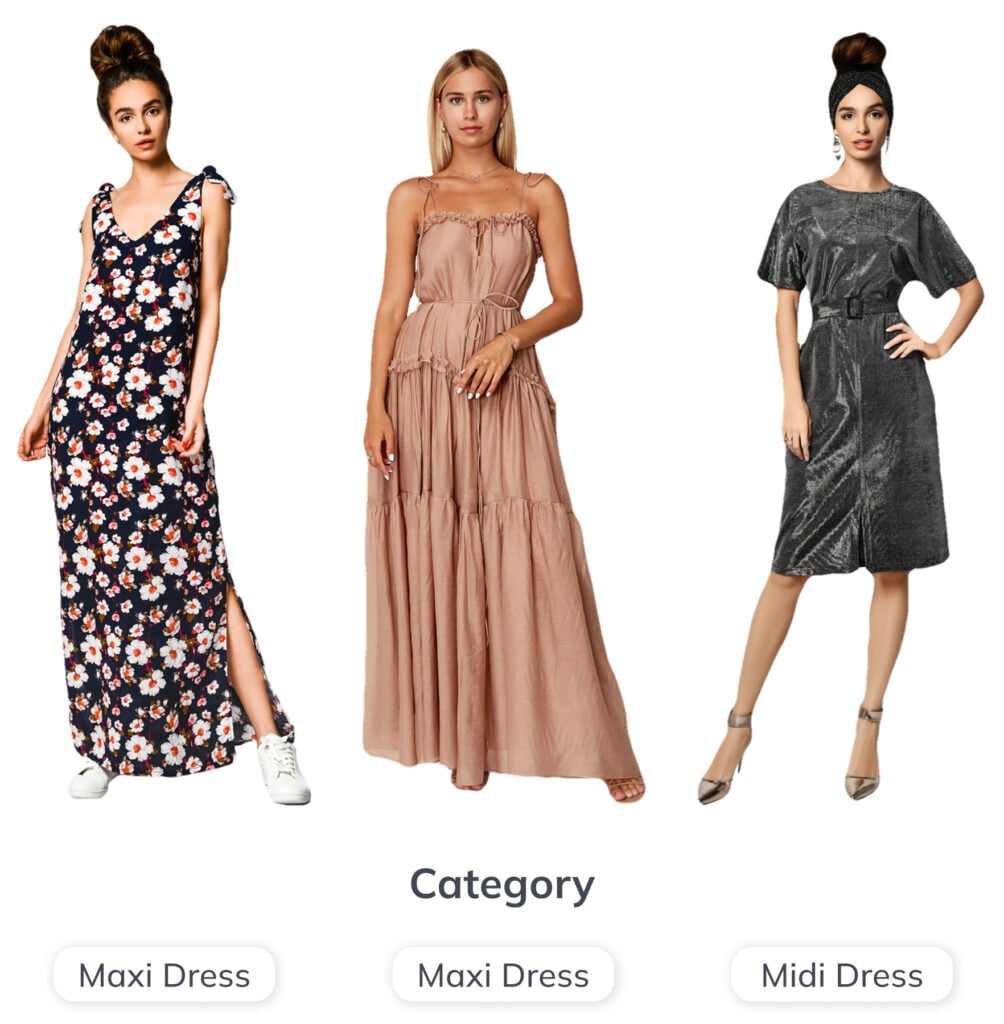
Image categorization assigns each image a category. The categories are visually distinctive, and each image belongs only to one. Initial image categorization is the foundation of most visual recognition pipelines in e-commerce, manufacturing, and other industries.
WHAT IS TAGGING?
Tag every image with many tags
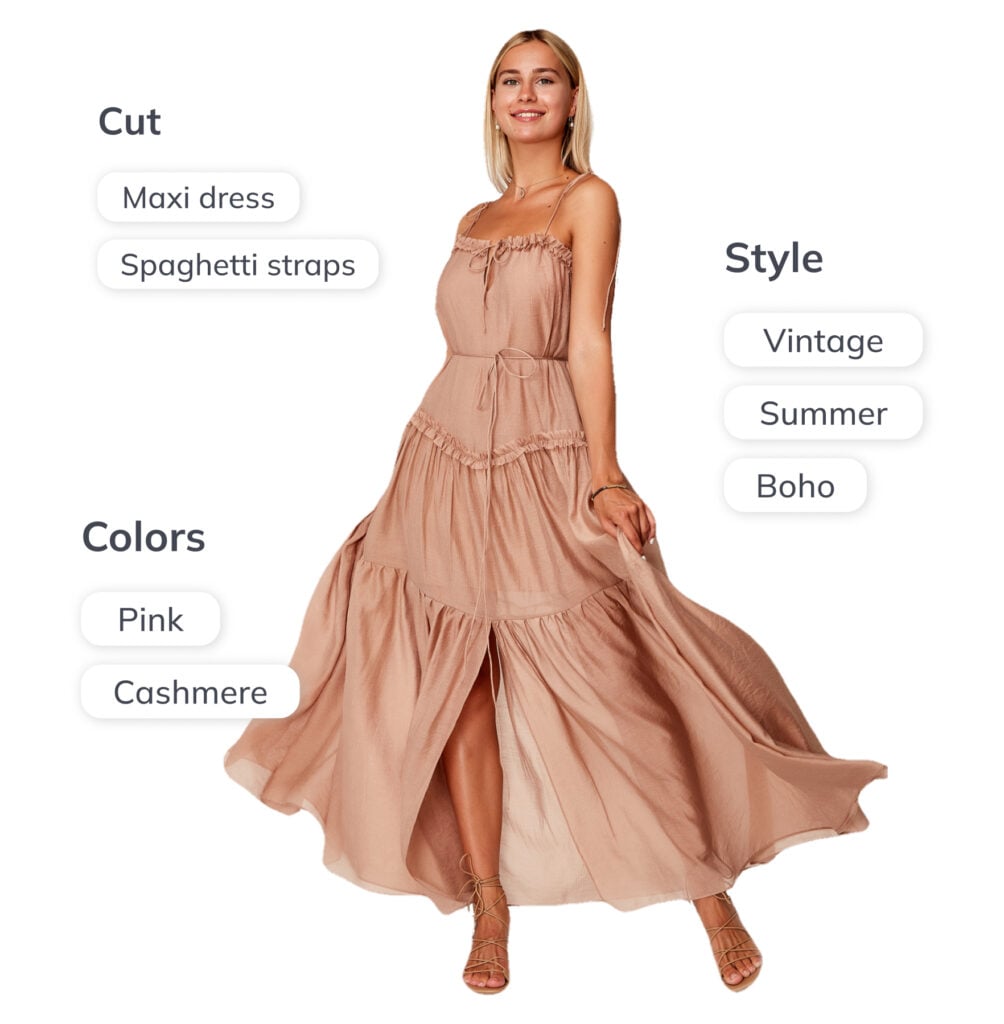
Image tagging assigns each image a number of descriptive tags. Multi-attribute recognition turns your image library into a structured, searchable dataset – every asset carrying a rich set of descriptors such as colour, pattern, material, and style.
Skip the setup with ready-to-use solutions
Check out our ready-to-use tools for fashion, home decor, collectibles, and more.
They can be used right away or combined with custom models into a single pipeline.
Image Regression
A specialized recognition system for evaluation, grading, and value prediction from images.
IMAGE REGRESSION
Automatic Prediction of Size, Age, or Rating From Images
Image regression uses deep learning algorithms to predict numerical values within a defined range directly from your images. It is used for quality control and to estimate values such as age, size, worn-out level, or rating – delivering consistent output for scoring & grading tasks.
You can train regression models under Image Classification in Ximilar App (create a new task: regression). We can also build a value prediction system tailored to your specific use case.

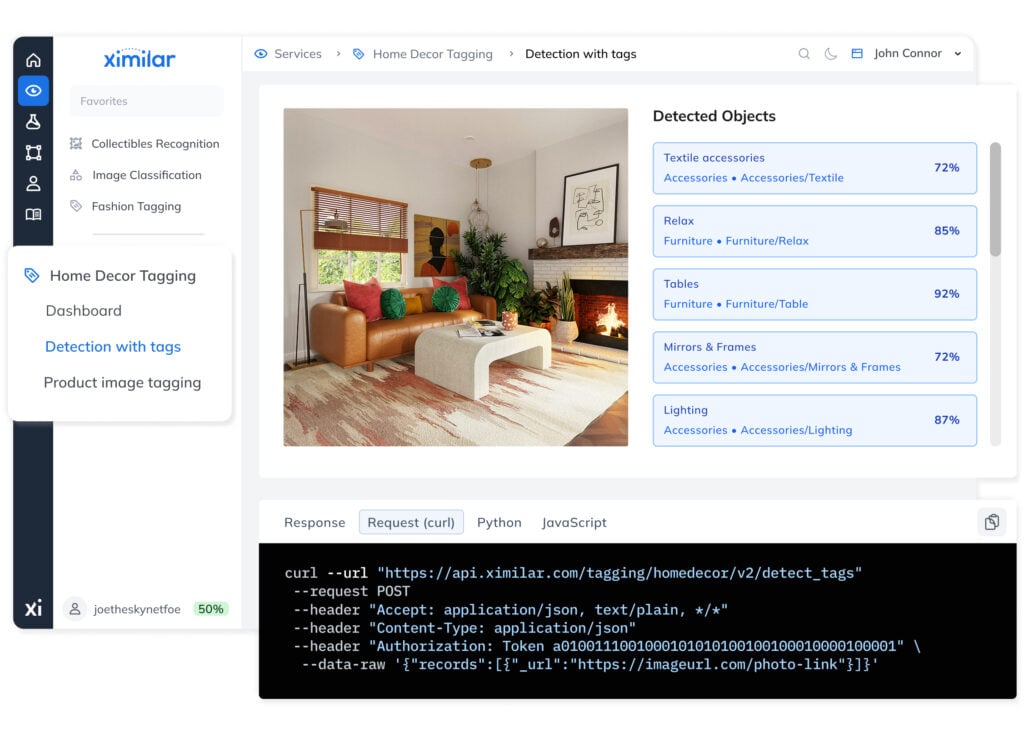
Object Detection
Object detection automatically finds different types of objects in images and marks them with bounding boxes, enabling analysis of complex images at scale.

OBJECT DETECTION
Train AI to Spot Any Object
Train custom object detection models (CenterNet) to identify any object, such as people, cars, particles in the water, material imperfections, or objects of the same shape, size, or colour.
Unlike open-source libraries such as OpenCV, Ximilar’s fully managed, no-code environment lets your engineer focus on results rather than infrastructure. Object recognition can also be combined with automatic tagging and other tasks to optimize multistage pipelines with a single API call.
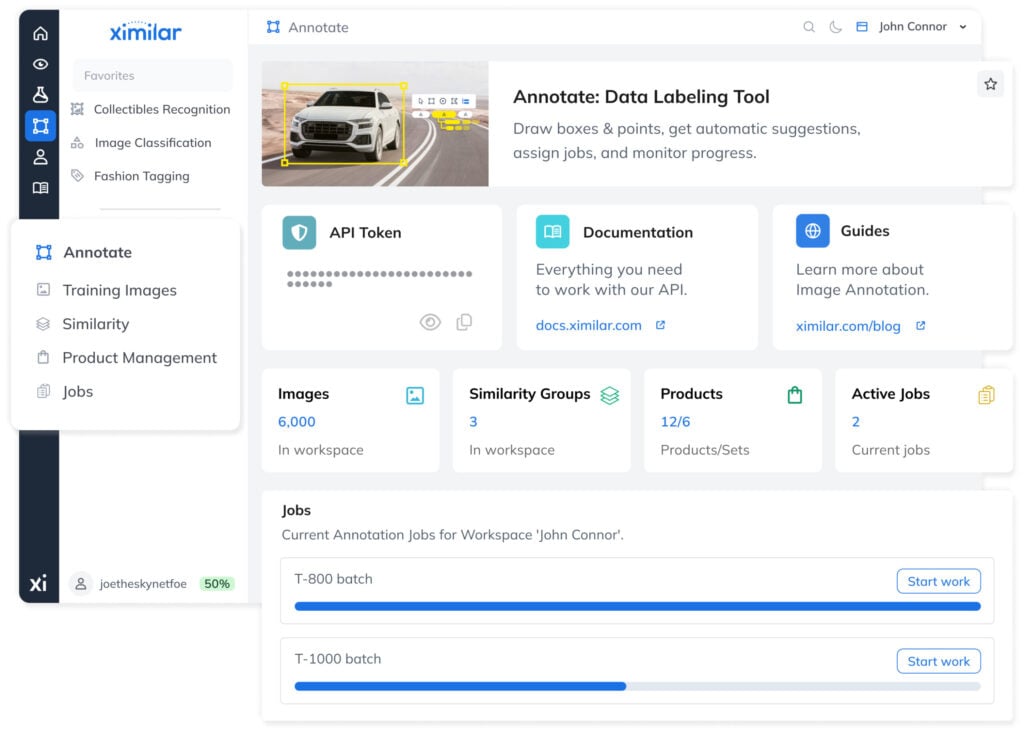
IMAGE ANNOTATION TOOL
Build High-Quality Training Datasets as a Team With Annotate
Annotate is Ximilar’s image annotation tool, fully integrated into the Ximilar App. It supports bounding boxes, polygons, AI-assisted suggestions, and complex taxonomy navigation via Flows – with every change instantly reflected across your workspace.
For larger projects, Annotate adds job queues, per-image verification, and multi-user task assignment – everything needed to supervise labelling at scale. Drawing and labelling objects do not consume API credits.
Q&A
How do I prepare the training data?
Training object recognition models requires larger datasets and more training time than classification. The process begins with data annotation – the manual marking of objects using bounding boxes. Precise and consistent labeling is one of the most important factors in recognition quality. Our computer vision platform accelerates this process via AI-assisted suggestions.
Q & A
How do you work with my data?
During training, your images are divided into a training set and a smaller validation set used to evaluate model performance before deployment. You can also upload an independent test set for final compliance checks and reporting. All data remains private and is never shared across accounts.
Vision Language Models
Fine-tune small, private AI models that understand both images and text – and deploy them on any hardware, including fully offline.
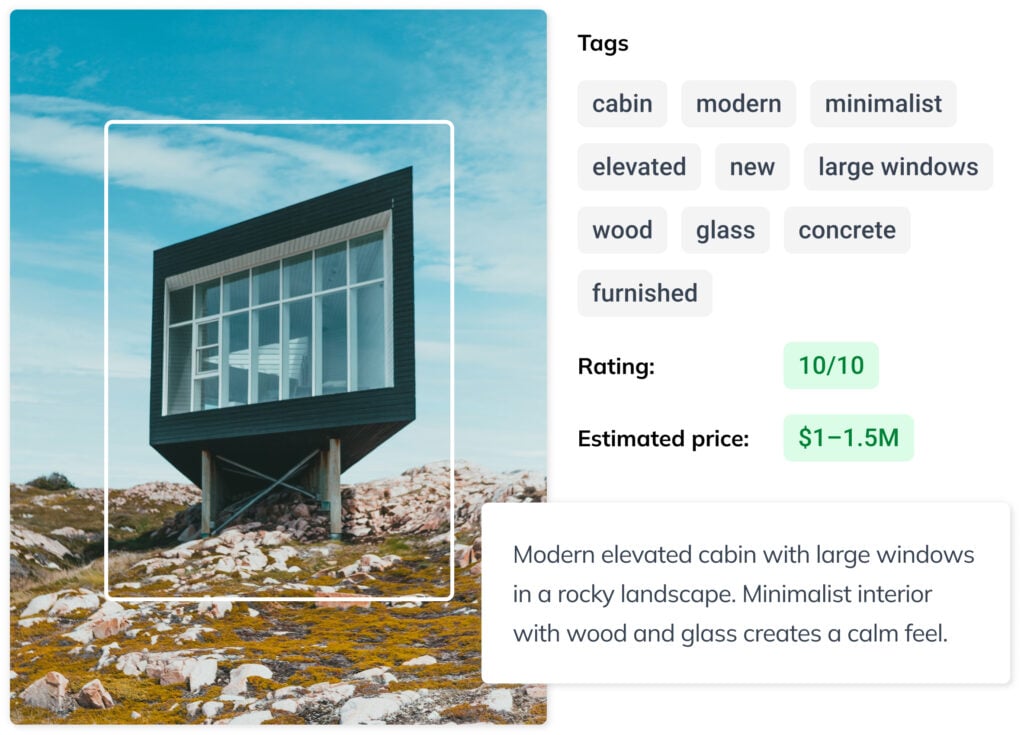
AI THAT READS AND SEES
Fine-Tune Vision Language Models Without Writing Code
Ximilar’s no-code VLM platform lets you train private AI models that combine computer vision with LLM capabilities – understanding both images and text without ML expertise. Fine-tuned models run on your own devices, handle domain-specific tasks, and deliver fast, accurate results.
Deploy on-premise or via REST API for complete control over data, privacy, and costs. Choose from open-source models, apply LoRA or full fine-tuning, and turn your visual data into actionable insights in just a few steps.
Flows: Combine Your Models
The key to managing complex computer vision applications is using multiple models working together as a coordinated system.
MODELS WORKING TOGETHER
Divide Complex Problems Into Simple Tasks
With Flows, models can be combined and chained in a sequence. Each image travels through your model pipeline until it is fully processed and labelled. This modular architecture means you can add, remove, or swap individual components without rebuilding your entire system.
Flows also power the smart labelling suggestions in Annotate guiding your annotator in real time. The result is faster, more consistent labelling and a tighter loop between training and deployment.
ENDLESS POSSIBILITIES
Change & Modify Your Tasks Anytime
-
Combine custom & ready-to-use solutions in a single pipeline
-
Re-train, add, or remove any model without downtime
-
Run recognition on individual objects isolated from the broader scene
-
Call multiple tasks in one request, or run recognition in parallel to maximize throughput
-
Nest flows within flows to build complex computer vision systems
-
Reuse one flow across multiple contexts – ideal for any builder managing several projects
Build rich hierarchy
Define a flow with a few clicks, then use it for both training and automation.
Play with the features
Add, remove, change, or duplicate components freely.
Make changes on the fly
Flow structure adapts to changes in your data and connected models.
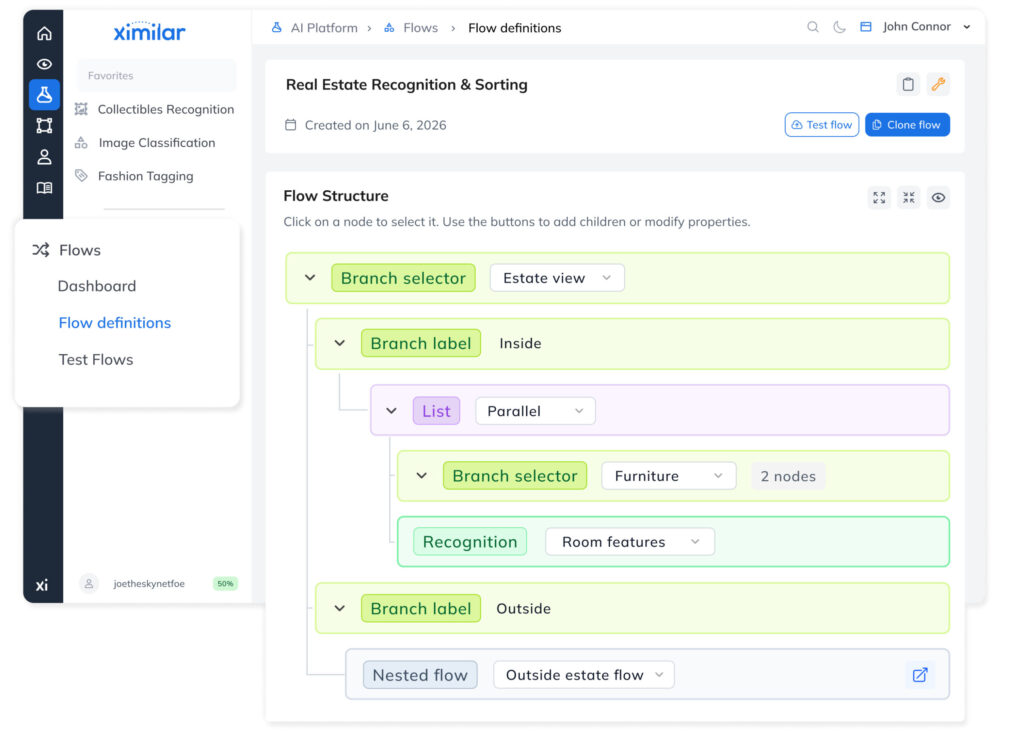
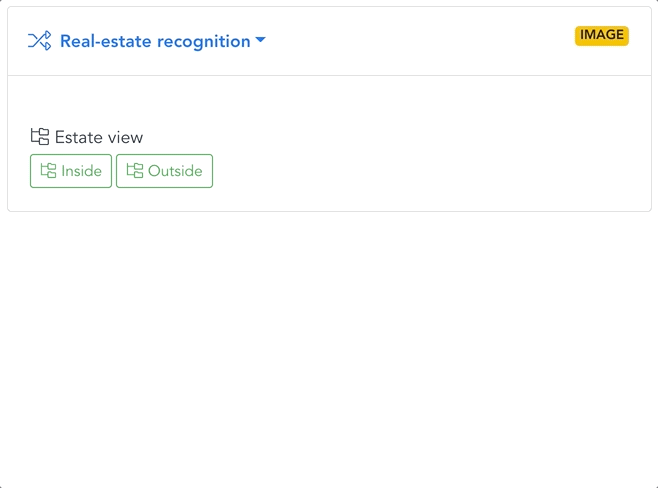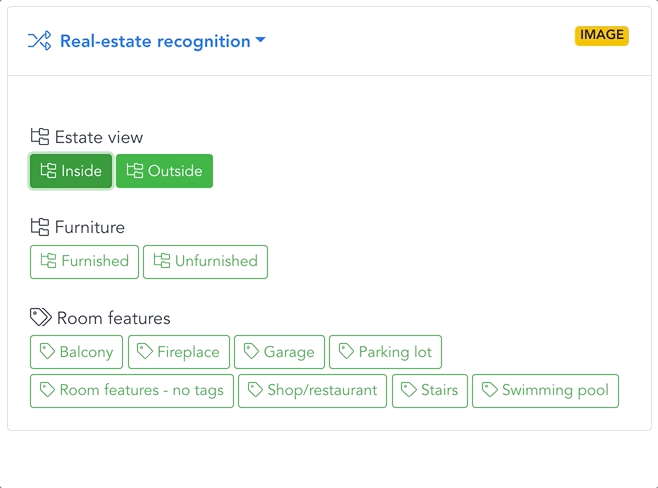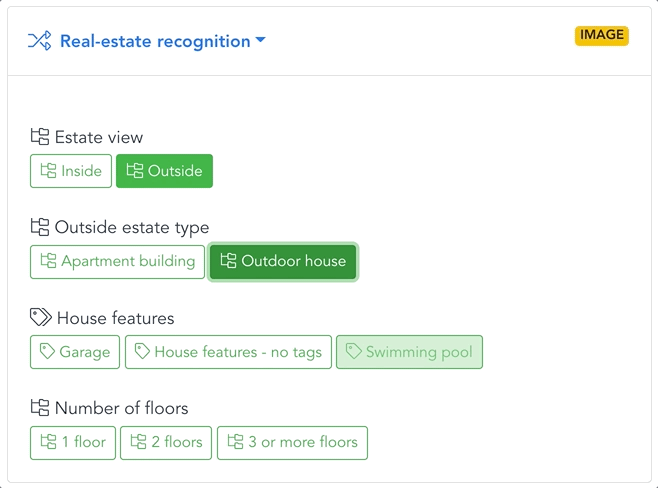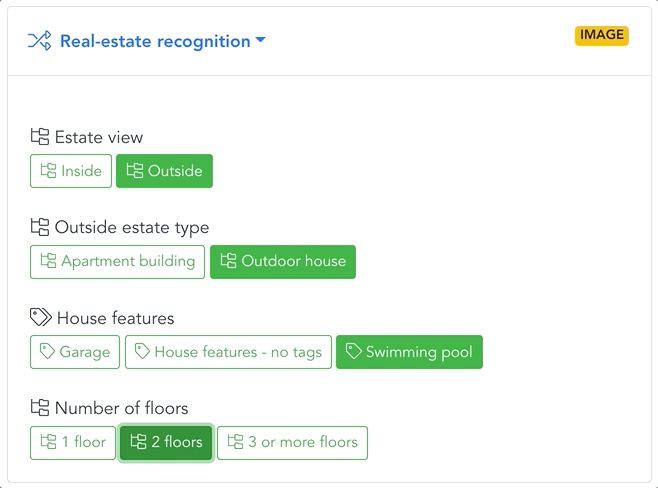
EXAMPLE: REAL ESTATE
Conditional image processing
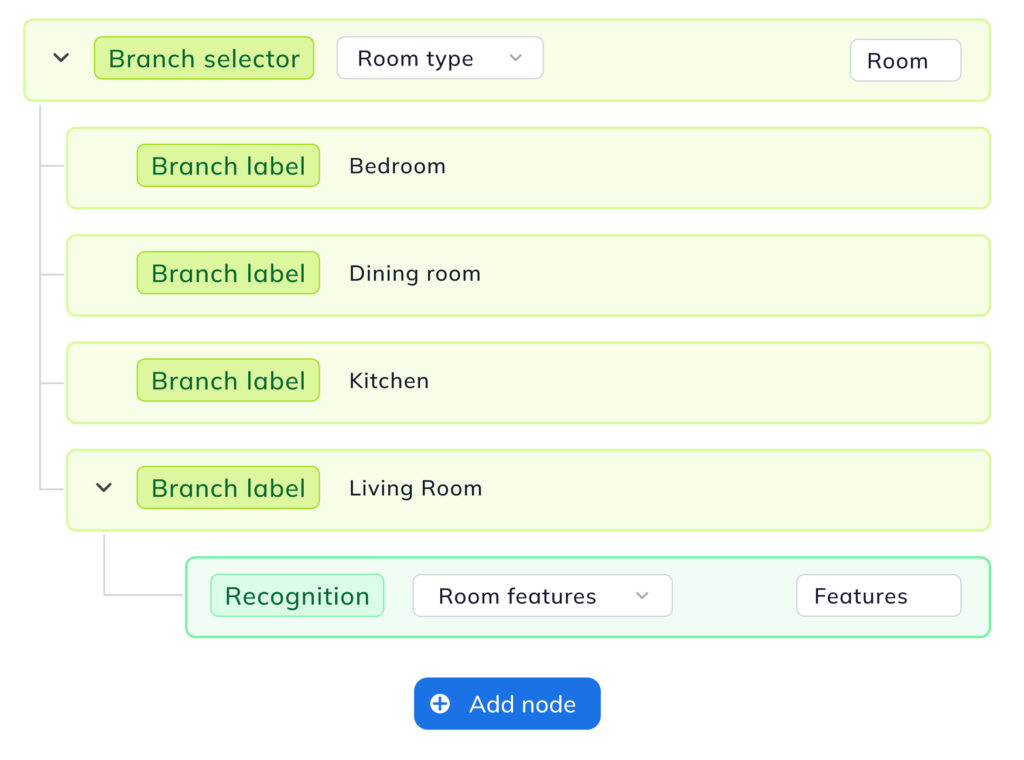
Imagine you are building a real estate platform. The first models in your flow filter out all images that don’t meet selection criteria – pictures without real estate, rooms, or furnishings. This reduces downstream inference costs and server load, accelerating the overall pipeline.
EXAMPLE: REAL ESTATE
Automatic filtering, sorting & tagging
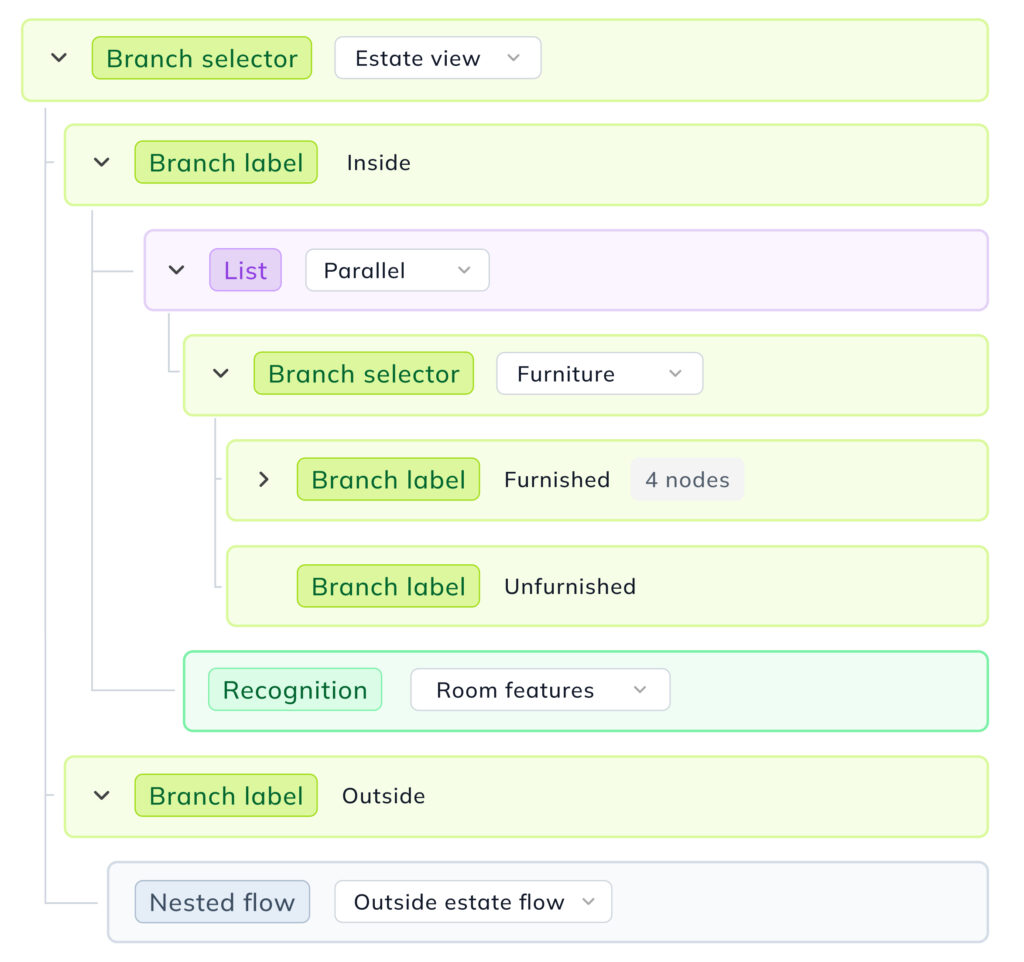
Images that pass the filter are gradually sorted with increasing precision. A first model separates apartments from houses. Apartments are sorted by room type, design, and furniture decor; houses by style, area, garden, or pool.
Be Ahead of the Competition
Unlimited number of images
No limits on the number of images per model or category — the system scales with your data, not against it.
Use one image for many models
The same images can be used to train multiple models, maximizing the value of every asset in your collection.
Built-in data augmentation
Built-in augmentation handles data preparation automatically, enabling robust model training even from lightweight datasets.
No charges for model training time
Unlike the competition, Ximilar doesn’t charge for training time — so teams can iterate freely, iterate aggressively, and retrain as often as the data demands. This is valuable for teams running frequent model updates.
No fees for deployed models sitting idle
You only pay for actual usage, making Ximilar cost-efficient for both high-volume enterprise deployments and smaller teams still validating their model before committing to full-scale rollout.
The fastest AI inference on the market
Image processing takes around 300 ms, compared to 2–3 seconds on competing platforms. Cached model serving eliminates cold-start delays, with GPU acceleration available for high-throughput workloads.

TECHNOLOGY STACK
We use state of the art neural network models & machine learning techniques
Our AI is constantly improving, so you always have access to up-to-date computer vision technology. Ximilar is a complete AI software suite built for various industries, combining recognition, search, and extraction capabilities in a single suite. Each model has millions of parameters that can be processed by CPU or GPU.
Our algorithm selects and applies the best-performing models for each task. We use the latest techniques, including TensorFlow or OpenVINO, as part of a broader advanced AI stack. Beyond image recognition, the platform supports OCR pipelines and works with LLMs for automated text generation, as well as AI agents for multi-step, multi-modal workflows where language and vision models work together.
Frequently Asked Questions
What does categorization, tagging, tags, and labels mean? What is the difference between categorization and tagging?
Automatic categorization is a process in which every image is assigned to a single category by a trained AI algorithm. The categories are visually distinctive — for example, dress vs. trousers. E-shops and enterprise catalogues typically use hierarchical taxonomies, working with both categories and subcategories.
Automatic image tagging assigns multiple attributes to each image — colour, pattern, design, style, material, and length. A dress image might be categorized as a casual dress and tagged with a rich set of descriptors simultaneously. This means even large collections can be fully enriched without manual effort.
In the context of categorization and tagging, a label describes both categories and tags. Object recognition works with bounding-box labels that identify located objects or people within a scene. Ximilar provides ready-to-use computer vision services such as Fashion Tagging and Home Decor Tagging, as well as a complete system for training custom models from scratch.
How can I train my own categorization & tagging model?
Log in to the Ximilar App and follow our step-by-step guide. No technical background is required — the system is designed so that domain experts, not just specialists, can train, evaluate, and deploy production-ready models.
Read more:
- How Ximilar technology works?
- Is there a difference between a task and a model?
- Can I use one task (model) in multiple Flows?
- How do I connect to Ximilar API?
- How do I evaluate the quality of my models? What are evaluation metrics?
- What is A/B testing of machine learning models?
- What is a machine learning loop?
Is the number of labels per task limited?
Technically, no. However, using hundreds of categories requires a correspondingly large image collection. For complex taxonomies, we recommend building a hierarchy of models and connecting them with Flows — this is how enterprise-scale systems are structured. Each element can be retrained and updated independently.
Can I combine machine learning models or put them in a sequence?
Yes. Flows help you to chain models in a sequence, combine them in parallel, put them in a hierarchical structure, and implement conditional logic. This is the core principle behind flexible visual recognition on Ximilar, accommodating new capabilities without disrupting existing workflow.
What is image labelling, and when do I need it?
Object recognition model training requires a labelled image collection. Labelling images means drawing bounding boxes around the objects that need to be located — precise and consistent markup is the single biggest determinant of recognition performance. In the Ximilar App, you can mark up images directly with Annotate, the advanced labelling tool built into the App.
Go to:
What is Annotate? How does it work?
Annotate is an advanced image labelling tool by Ximilar, fully integrated into the Ximilar App. It is built for fast, precise labelling of large training collections at speed. It shares the same back-end and database as the rest of the App — so every mark-up and verification is instantly reflected across your workspace.
You can upload images through the App and mark them up in Annotate. Assign jobs to teammates, set verification requirements, and track progress — all within the same environment you use for training and rollout. A clean, end-to-end process from raw data to production.
What is the difference between labelling in Ximilar App and Annotate?
Both share the same core principle: view an image, select the recognition task, check or draw bounding boxes, and assign categories from your hierarchy. Both can be used to create and train tasks — they are two modes within the same computer vision toolset, not separate products.
The App excels at entity creation, data upload, model training, and bulk actions. Annotate is optimised for processing large volumes of training images precisely and fast, with intelligent job queues and multi-user verification — giving team leads full insight into labelling progress and consistency.
For large projects where a category hierarchy is already in place, upload images in the App and switch to Annotate for the actual labelling work.
Does Annotate support work in a team or multiple accounts?
Yes. Your company account can have multiple workspaces, each isolated for a separate project. Team members get access to the workspaces relevant to their work, and the workspace switcher in the top right corner of the app applies everywhere in the workspace. Workspaces are also accessible via REST for programmatic data management — useful for teams managing labelling across multiple server environments.
How do I evaluate the quality of my models? What are evaluation metrics?
Each model is automatically evaluated on an evaluation dataset during training. You can also upload a separate test set for independent measurement.
In the App, navigate to your task, open the model detail view, and review evaluation metrics — precision, recall, confusion matrix, and failed images — giving you transparent, actionable insight into model output. Based on these metrics, you can further iterate and improve your training dataset to make your model more robust. We are also able to change the architecture of the neural network if needed and improve the robustness for your specific data.
You can also test a model on any individual image by dragging and dropping it or pasting a URL into the Test panel under your service.
Go to:
What is A/B testing of machine learning models?
A/B testing lets you compare the performance of a new model version against the current production build using real traffic or held-out data. It is the recommended way to validate improvements before committing to a new deployment, ensuring every update is a measurable step forward.
What is mAP metric of object detection models?
The mAP, or mean average precision (AP) is the standard evaluation metric describing the precision of your object detection models. It combines precision, recall, the precision-recall curve, average precision, and IOU (the algorithm that measures bounding box overlap) into a single score per label.
You can find mAP per category in your workspace under Object Detection > Tasks > Models in the model detail view.
Is there a difference between a task and a model?
Task refers to the type of problem being solved — image classification, object recognition, or regression. It defines the category set and training configuration. In our documentation, a task represents the starting point for your machine learning project. It serves as the abstract definition for training a recognition model and includes a set of labels, which can each be assigned to multiple training images. Your tasks, data, and images are private and accessible only to you.
Model is the trained result (of a task) — a deep model trained on your images and ready for inference. Each model includes an accuracy metric measured at the end of training.
Models are private to their owner, and each time you retrain, a new model version is created with an incremented version number. You can choose which version to deploy in production. Read How Ximilar technology works? for details.
What is a machine learning loop?
Any image processed by a deployed machine learning model can be saved to the workspace and used to retrain the model to improve it. The retraining is done manually after annotators check these new images. Then the new, better and more accurate version of the model is deployed. This loop improves the accuracy of your model in the long term, especially if the character of the data changes over time (e.g. the lightning of the scene changes dramatically). See pricing for details about availability.
Go to:
What is custom image recognition?
Image recognition is the technology that analyzes an image and describes its content — categorizing it, tagging its attributes, or locating specific objects within it.
Ximilar provides two options:
- Choose from off-the-shelf solutions for the detection, recognition, tagging, and sorting of specific image data, such as stock photos, home decor and furniture images, fashion photos, or trading and collectible cards.
- Train your own custom image recognition models on Ximilar’s computer vision platform without coding. Namely, you can train:
- image classification models: categorization & tagging, image regression (value prediction)
- object detection models
The custom models can be easily combined with existing ready-to-use solutions with Flows. Object detection requires manual annotation of training data, which can be done in the dedicated interface Annotate. The result is a full suite of visual capabilities that can be assembled, tested, and available in days rather than months.
Custom image recognition systems underpin computer vision pipelines across retail, healthcare, security, manufacturing, and beyond. Related capabilities such as OCR extend this further, extracting text from images for document processing and product data workflows.
Go to:
Read more:
- Which services does Ximilar provide, and what are the differences between them?
- How Ximilar technology works?
- How can I train my own categorization & tagging model?
- Can I combine machine learning models or put them in a sequence?
- Can I combine visual search algorithms with custom models created with Ximilar platform?
What is the use of image recognition in retail?
In retail, image recognition is pivotal in optimizing operations depending on visual data processing. One significant application lies in inventory management, where it automates tracking products and stock levels, streamlining restocking processes and minimizing manual effort.
Additionally, image recognition helps with consumer research, enabling retailers to gain insights into customer demographics and behaviour within physical stores. This information aids in optimizing store layouts, product placements, and staffing strategies to enhance the overall shopping experience.
Image recognition also supports personalized marketing initiatives by analyzing customer preferences and purchase history, allowing e-shops to tailor promotions and recommendations accordingly. This personalized shopping experience fosters stronger customer engagement and increases sales.
In many of these applications, image recognition works in tandem with visual search technology, which identifies visually similar products to items detected in product photos and real-life images.
Go to:
Read more:
In which fields does image recognition help?
Image recognition technology finds widespread application in diverse fields such as healthcare, retail, and security systems.
In healthcare, it aids in the interpretation of medical images, assisting clinicians in diagnosing diseases and identifying anomalies with greater precision. Read about some of our use cases here.
Similarly, in retail, image recognition streamlines checkout processes and, together with visual search, enhances customer experience through personalized recommendations.
In security, it strengthens surveillance systems by enabling real-time monitoring, threat detection, and facial recognition.
This technology is also essential for autonomous vehicles, enabling them to perceive their surroundings through cameras and sensors, recognize objects, pedestrians, and road signs, and make real-time decisions for safe navigation.
Additionally, image recognition systems help in both research and applied sciences. For instance, in biological research, microscopy image analysis and wildlife conservation. It plays a crucial role in monitoring and protecting endangered species. It enables researchers and conservationists to analyze vast amounts of camera trap data efficiently, identifying and tracking individual animals, assessing population dynamics, and detecting potential threats such as poaching or habitat loss.
Image recognition aids satellite imagery analysis, especially in monitoring vegetation coverage crucial for sectors like insurance and agriculture. LAICA, by World From Space (WFS) and Ximilar, addresses this, using deep learning to merge satellite data for daily vegetation monitoring despite cloud cover challenges.
In social media, image recognition facilitates image tagging and content moderation.
What factors determine the accuracy of the image recognition system?
The two key factors determining the accuracy of the image recognition task are the complexity of the task and the quality and quantity of the training data available.
Clean, consistently labelled data matters more than algorithm choices alone. For tasks such as OCR, additional pre-processing steps can be used to optimize input quality. Ximilar makes it straightforward to evaluate, iterate, and optimize your models over time.
What image classification techniques does the Ximilar platform offer?
The system supports single-category classification, multi-attribute tagging, and value regression — all accessible from a unified environment.
Every model type shares the same training, evaluation, and deployment pipeline, so switching between them requires no additional configuration.
What is a vision language model (VLM) and how does it differ from a standard LLM?
Unlike traditional computer vision models — narrow artificial intelligence designed for a single task — VLMs handle many tasks in one. Traditional CV models like object detection or image captioning tools couldn’t process language; a VLM unifies image processing and language in a single architecture.
A vision language model (VLM) is a generative model that processes both images and text simultaneously — replacing multiple specialized tools with a single model. Where a standard large language model (LLM) works with text alone, a VLM combines vision and language encoders — typically a vision transformer (ViT) paired with a language decoder — enabling the model to interpret visual input and generate structured text responses from it.
In practice this means VLMs can answer questions about an image, extract structured data from documents, classify products from photos, or generate captions — all tasks simply out of reach for text-only models.
How does image recognition work?
Image recognition uses convolutional neural networks to extract features from images and map them to categories, attributes, or numerical values. These mappings are learned from labelled training examples.
Related tasks such as OCR use similar mechanisms to extract text, while localisation models identify and classify multiple regions within a single image in a single inference pass.
We provide a number of off-the-shelf solutions for classifying specific image data, such as stock photos, home decor and furniture images, fashion photos, or trading and collectible cards.
Custom models can also be easily trained on our platform. A developer can access every capability via REST using Python or any HTTP client, apply compliance controls at the workspace level, and manage the full model lifecycle — from training through to production — without touching any infrastructure. Read the articles in our blog to learn about image recognition technology.
What are Flows?
Flows are Ximilar’s technology for chaining, combining, and structuring models into scalable, production-ready systems. Flows help you assemble complex image processing logic without writing orchestration code — and without managing the servers that run it.
How does the Ximilar VLM platform compare to alternatives like OpenAI, OpenPipe or Ertas?
Ximilar lowers the barrier to building and owning a production-ready multimodal model — no coding, no ML expertise, no dependency on third-party APIs, and no ongoing per-call costs. You configure your task, build your data set, fine-tune your model, and run it on your own infrastructure.
Guided setup. The Wizard walks you through initial configuration — base model selection, system prompt, token limits, augmentation — in a clear way. Once set up, you focus on building good samples.
Data management. Most competing platforms treat data preparation as something you handle outside their system, typically via API only. Ximilar supports dataset building and management both through the app interface and the API. It consists of samples with prompts, result templates, and typed variables like {{category}}. Predefined variables keep inputs consistent, form-based entry simplifies annotation, and the result is clean, well-structured training data — which is what produces models that perform reliably in production.
Iterative workflow. You can refine your data, retrain, evaluate, and gradually improve your model until it performs precisely on your task. This is available both through the interface and the API.
Model ownership and offline deployment. OpenAI allows fine-tuning but model weights cannot be downloaded. Hugging Face AutoTrain supports training and exports model weights, but open-source models like those on Hugging Face focus on text and standard image classification — not vision language models that combine image and text. Replicate supports a broader range of vision models but operates on pay-per-inference pricing. Ximilar lets you export in Safetensors, GGUF, or .pt format and run via the Transformers library or llama.cpp, fully offline, on your own hardware.
Pricing. Training is billed per operation: 10,000 credits for a 450M LoRA run, up to 30,000 for a 4B model, with model conversion at 10,000 credits. Once your model is running locally, inference has no additional cost.
Why train a custom VLM instead of using generic model like GPT or Gemini?
The most compelling reason is cost. Commercial APIs like GPT or Gemini charge per token on every request — at production scale, those fees compound fast. A trained model runs on your own hardware after a one-time investment, meaning inference costs nothing per call.
Beyond cost, generic models are trained for breadth, not your business. They have no knowledge of your product taxonomy, document layouts, medical terminology, or domain-specific edge cases. Once a model is trained on your own image-text pairs, it learns those implicit rules directly from examples, consistently outperforming generic models on your specific tasks.
Which services can I combine with Flows? What are Actions?
Flows were made to combine different tasks into complex image processing systems.
A Flow is assembled from the following action types:
- Branch Selector – routes images through different branches based on recognition results
- Recognition – runs a classification task and returns structured results
- Object locator – runs a recognition task and returns bounding boxes and categories
- Object Selector – isolates detected objects for independent downstream processing
- Ximilar Service – calls any ready-to-use visual service
- List – runs multiple actions in sequence or in parallel
- Nested Flow – calls another Flow
Go to:
Can I use one task (model) in multiple Flows?
Yes. A single trained model can be referenced by multiple Flows. Add the appropriate action type and select your task — no duplication of training data or model resources required.
What is the use of image recognition in healthcare?
Image recognition helps optimize diagnostics, treatment, as well as patient care by employing advanced AI algorithms to identify anomalies, recognize tissue features, or flag cases for clinician review.
It facilitates early disease detection, personalized treatment plans, and efficient workflows for healthcare providers. Key applications include diagnostic imaging and disease detection, such as analyzing X-ray or microscopy images, as well as providing surgical assistance. Additionally, the technology helps with other vital use cases such as drug discovery and health data analysis.
Models run on shared cloud servers, enabling hospitals and research institutions to access advanced recognition capabilities without building and maintaining their own model stack.
Where do my training images go, and who owns the trained model?
Your data stays private and is never shared with third parties, nor it is used to improve other systems. Images are stored in AWS S3 storage.
You fully own the model you train. Once training is complete, you can download the model weights and deploy them anywhere: on your own servers, on an edge device, or in an air-gapped environment. There are no per-token fees, no vendor lock-in, and no restrictions on how or where you run it. This makes the platform well-suited for GDPR-regulated industries, healthcare imaging, legal document processing, and any case where sensitive visual data cannot leave your infrastructure.
Can I have multiple Flows?
Flows are available on all pricing plans. The number of Flows you can create depends on your subscription tier — check our Pricing page for details.
Go to:
Is training, deployment and using Image Recognition tasks charged?
No. Training custom models is completely free, as is deploying them. Ximilar charges neither for training time nor for idle time — only for actual inference. This makes it cost-efficient for enterprise teams running continuous updates and for smaller teams still validating their model before committing to full-scale rollout.
Go to:
How do I deploy my trained model and can I run it offline?
The platform offers two deployment paths depending on your infrastructure requirements.
- Via REST API – Once training is complete, your model is available on a managed endpoint. Send an image and a text prompt as input and receive structured outputs instantly, with no infrastructure to manage on your side. This is the fastest path to integrating your model into an existing application.
- Offline/on-device deployment – export your model weights and run the model entirely on your own hardware — a local server, an edge device, or a machine with no internet connectivity.
Models can be exported in Safetensors, GGUF, and .pt formats and run via standard frameworks including Transformers and llama.cpp. This path offers fixed, predictable costs, full control over data handling, and the lowest possible latency for real-time applications such as drone vision or medical imaging in clinical settings.
Do I need to write any code to train and deploy on Ximilar?
No. Ximilar offers no-code training for vision language models. The entire workflow — data collection, training, and deployment — is managed through a guided interface with no Python, Docker, or ML expertise required.
You define your task using the Wizard, which walks you through selecting a base model, configuring your system prompt, setting token limits, and preparing augmentation. Training samples are added via a form-based interface where variables such as {{brand}} or {{category}} define the output structure. Unlike generic APIs, these models are designed around your specific data and task.
For teams that prefer to work programmatically, the full workflow is also available via the Ximilar API. You can upload annotated samples, trigger training runs, and manage tasks through standard REST calls — useful for automating data pipelines or integrating VLM pipelines into existing systems.
Can a training sample include multiple images, and when would I use that?
Yes, each sample can include up to 10 images. This is useful when your task requires analysing several images together to produce a single, accurate output — rather than evaluating one image in isolation.
A practical example is real estate analysis. A single property listing might have photos of the living room, kitchen, bedroom, and exterior. Instead of processing each image separately and combining results manually, you can include all of them in one sample. The model uses the full set of images as context, which leads to more accurate and complete predictions than any single image could provide on its own.
Use multiple images per sample whenever the correct output depends on information spread across more than one image.
How much training samples do I need to fine-tune a VLM?
Far less than most people expect. Using LoRA (Low-Rank Adaptation), many models can be trained with as few as 200 to 1000 labeled image-text examples and still produce reliable, domain-specific results. LoRA for VLMs updates only a small subset of model parameters, making it fast, affordable, and accessible even to teams without ML expertise.
For more complex tasks—such as document extraction from variable layouts, multi-label classification, or nuanced image captioning—larger datasets of several thousand samples ensure maximum performance. Full fine-tuning, which trains all parameters of the multimodal model, is better suited to these cases.
As a rule of thumb: start with a few hundred samples, evaluate, and scale your dataset only if benchmark results show room for improvement.
I know what I need, but I’m not sure how to build a Flow.
Need help with setup? Watch the video tutorial or read the guide below. For teams that need a production-ready system without the setup overhead, we can prepare a demo on your own data and deploy the full pipeline from labelling through to REST access.
What does Ximilar’s VLM platform cost, and what am I charged for?
Ximilar uses a credit-based model rather than a subscription. You purchase a monthly plan that includes a set number of API credits, and you spend those credits only when you actually use the platform — no charges for training time, deployment, or idle time.
Credits are consumed for the following operations:
- Adding a sample — 5 credits per sample
- Training a model — 10,000 credits for a 450M model, 20,000 for 2B, 30,000 for 4B
- Model conversion (exporting weights) — 10,000 credits
Once your model is exported and running on your own hardware, inference costs you nothing — there are no per-call fees of any kind. If you need extra credits beyond your monthly plan, non-expiring credit packs are available as a top-up.
This is a different model from subscription-based platforms like Ertas, which charge a fixed monthly fee regardless of usage. With Ximilar, you pay for what you use, and the largest cost — inference at scale — moves to your own infrastructure.
What is the difference between LoRA and full fine-tuning for VLMs?
LoRA (Low-Rank Adaptation) is the most efficient approach. Adapting models requires only a small set of adapter weights to be updated — it freezes most parameters, making it faster, cheaper, and ideal for most domain-specific cases.
LoRA for VLMs preserves the general language understanding and vision capabilities of the base model while adapting its outputs to your domain. Training costs start from roughly $10 for smaller models and scale up from there.
Full fine-tuning updates all parameters on your data. It is more resource-intensive and requires more labeled examples — models may need thousands of samples for the most complex cases — but enables maximum accuracy for tasks that require deep domain knowledge.
For instance, specialized document extraction, medical imaging analysis, or applications where the base model’s general priors would interfere with domain-specific patterns. The model can also be incrementally retrained as new data becomes available, keeping it current without starting over.
What real-world tasks can fine-tuned VLMs handle?
Fine-tuned VLMs automate a wide range of production workflows across industries. Common use cases on the Ximilar platform include:
- Document processing — structured extraction of fields from invoices, contracts, purchase orders, and PDFs, using vision and text understanding to handle variable layouts without rule-based templates.
- Retail and e-commerce — automated product classification, attribute tagging, and caption generation from product images, replacing manual cataloguing at scale.
- Medical imaging — on-premise analysis of radiology scans, dermatology images, or pathology slides, where sensitive data cannot leave the clinical system.
- Real estate — classification and visual inspection of property listings, identifying features from photos to populate structured listing data automatically.
- Manufacturing and quality control — detection of sub-millimeter defects on production lines, reading damaged or partially obscured labels, and flagging anomalies in aerial or drone footage.
In all these scenarios, VLMs bridge computer vision with language reasoning, consistently outperforming both rule-based CV pipelines and generic large language model solutions.
What do I pay for when using the Flows?
Creating Flows and chaining tasks costs nothing. Credits are consumed only when inference is performed — when your models process images. Plan-level limits apply to the number of Flows; check our Pricing page to find the right tier.
Go to:
How long does the VLM training take?
It depends on the size of your data set and the base model you chose. For a compact model like LFM2-VL with a few hundred samples, training typically completes within a few hours. Larger models fine-tuned on thousands of samples can take longer — up to a day or more in some cases.
You don’t need to monitor the process. The platform handles training in the background and notifies you when your model is ready.
Which open-source base models does the Ximilar platform support?
The platform currently supports several leading open-source VLMs built on proven foundation models, each suited to different requirements:
- Liquid AI provides compact and efficient multimodal models built on a vision transformer architecture and designed for edge deployment. They deliver strong performance with minimal compute, making it ideal for production systems where resource constraints matter and for running VLMs directly on device.
- Gemma (Google DeepMind) provides broad language support across more than 140 languages and handles a variety of tasks and modalities with balanced performance.
- Qwen-VL (Alibaba) is one of the newer models with advanced vision, strong spatial reasoning, and OCR support. Models like Qwen — including the 72B model variant — rank among the top open-source VLMs on standard benchmarks. Llama 3.2 Vision rounds out the lineup as one of the leading open models, well-suited to a variety of multimodal tasks.
New models are added to the platform regularly.
Can I build a separate evaluation dataset to test my model?
Yes. Any sample can be flagged as a test sample. The platform then uses these samples exclusively for evaluation — they are held out from training and used to measure how well the model performs on data it hasn’t seen.
This gives you a reliable picture of real-world performance before you deploy. You can manage test flags through the interface and the API.
What happens to previous model versions when I retrain?
Nothing is overwritten. Every training run is saved as a new numbered version within the task. You can see the full history — version number, training date, and accuracy — at a glance. Only one version is active at a time, but you can switch freely using the Activate button.
This makes it straightforward to compare iterations, roll back to an earlier version if a new one underperforms, or keep a stable production version active while experimenting with updated data. The Auto deploy option automatically activates the latest version as soon as training completes.
What is augmentation and should I use it?
During training, the platform can automatically generate modified variants of your images — cropped, flipped, rotated, color-shifted, and so on. This is called augmentation. The purpose is to expose the model to more variation without requiring you to collect additional data, improving its ability to generalize to real-world images.
The available options are: random crop, 90° rotation, horizontal and vertical flip, quality augmentation (adding noise or varying JPEG compression), random erase (blanking out random rectangles), color mutation (low to high), and free rotation up to a specified degree.
The general rule is to enable any augmentation that reflects variation your model will actually encounter in production. If your images can appear at any orientation, enable rotation. If lighting and camera quality vary, enable quality augmentation and color mutation. Avoid augmentations that would distort features the model needs to recognize — for example, if text orientation matters for OCR, random rotation may hurt more than it helps.
My model isn’t performing well. What should I do?
There are a few common reasons a fine-tuned model underperforms, and each has a straightforward path forward.
The task may be too complex for the current setup. Some tasks require more nuanced understanding than a smaller model can reliably deliver. In that case, switching to a larger base model is the first thing to try.
The dataset may need more or better data. Model quality is directly tied to the quality of your training samples. If they are inconsistent, too few, or don’t cover the full range of variation your model will encounter in production, accuracy will suffer. Adding more diverse, well-annotated samples is usually the most effective fix.
You can always reach out. If you’ve iterated on your data set and model size and results are still not where they need to be, the Ximilar team is available to help diagnose the issue and suggest next steps.
Can multiple people collaborate on the same VLM task?
Yes. Ximilar platform is built with team workflows in mind. The platform uses workspaces, and each workspace can be shared with multiple users who work together on the same projects — building labeled samples, annotating, and managing tasks. This makes it practical for teams where annotation and model configuration are handled by different people.
One additional benefit: images uploaded to a workspace are shared across the platform. The same image can be used as a training sample for a VLM task and simultaneously used to train an object detection model — no duplication needed. All within your workspace so you have full control over your data.
How fast and efficient is the image recognition process?
Basic categorization and recognition models typically process an image in 5 to 100 milliseconds, depending on input resolution and CDN speed. Cached model serving eliminates cold-start delays — the quickest response is always ready. For high-throughput deployments, models can be further optimised to get the most from dedicated hardware.
Tips & Tricks
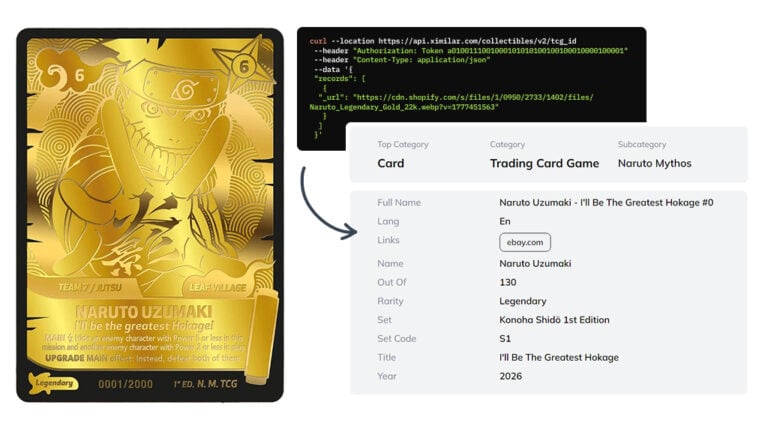
Naruto Mythos Card Recognition – Now in Our TCG AI
Ximilar’s card recognition AI now identifies English Naruto Mythos TCG cards – name, set, rarity, and other details returned directly from the API.
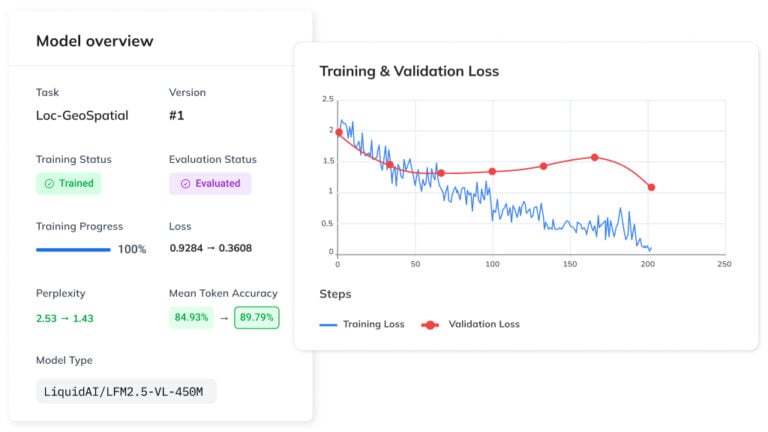
Vision Language Model Evaluation & Inspection Made Easy
From loss curves to GGUF exports – mastering your vision language model evaluation workflow with built-in metrics.
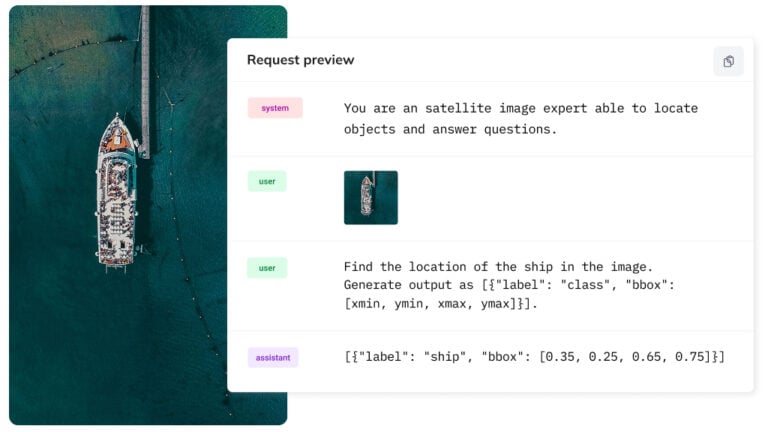
Fine-Tuning a Vision Language Model With the Ximilar API
Fine-tune your vision-language model with image understanding, run it on your own hardware, and cut your per-inference token costs.
Get Image Recognition API Now
We handle the model serving, infrastructure, and compute — and wrap it all in a few lines of code, so your team can incorporate visual recognition into any application without managing servers or dedicated hardware.
curl -H "Content-Type: application/json" -H "authorization: Token __API_TOKEN__" https://api.ximilar.com/recognition/v2/classify -d '{"task_id": "__TASK_ID__", "version": 2, "descriptor": 0, "records": [ {"_url": "https://bit.ly/2IymQJv" } ] }'import requests
import json
import base64
url = 'https://api.ximilar.com/recognition/v2/classify/'
headers = {
'Authorization': "Token __API_TOKEN__",
'Content-Type': 'application/json'
}
with open(__IMAGE_PATH__, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
data = {
'task_id': __TASK_ID__,
'records': [ {'_url': __IMAGE_URL__ }, {"_base64": encoded_string } ]
}
response = requests.post(endpoint, headers=headers, data=json.dumps(data)) if response.raise_for_status():
print(json.dumps(response.json(), indent=2))
else:
print('Error posting API: ' + response.text)$curl_handle = curl_init("https://api.ximilar.com/recognition/v2/classify");
$data = [
'task_id' => __TASK_ID__,
'records' => [
[ '_url' => 'https://bit.ly/2IymQJv' ],
[ '_base64' => base64_encode(file_get_contents(__PATH_TO_IMAGE__)) ]
]
];
curl_setopt($curl_handle, CURLOPT_CUSTOMREQUEST, "POST");
curl_setopt($curl_handle, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($curl_handle, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl_handle, CURLOPT_FAILONERROR, true);
curl_setopt($curl_handle, CURLOPT_HTTPHEADER, array(
"Content-Type: application/json",
"Authorization: Token __API_TOKEN__",
"cache-control: no-cache",)
);
$response = curl_exec($curl_handle);
$error_msg = curl_error($curl_handle);
if ($error_msg) { // Handle error
print_r($error_msg);
} else { // Handle response
print_r($response);
}
curl_close ($curl_handle);Ximilar is a reliable & responsible partner in image AI. We deliver what we promise.
Contact us now- Easy setup
- •
- Expert team
- •
- Fast scaling