OpenVINO: Start Optimizing Your TensorFlow 2 Models for Intel CPUs with Docker
Tutorial for optimizing your image recognition models with OpenVINO technology. Making your system faster with Intel CPUs.


In the previous article, we mentioned how OpenVINO improved the performance of our machine learning models on our Intel Xeon CPUs. Now, we would like to help the machine learning practitioners who want to start using this toolkit as fast as possible and test it on their own models.
You can find extensive documentation on the official homepage, there is the GitHub page, some courses on Coursera and many other resources. But how to start as fast as possible without a need to study all of the materials? One of the possible ways can be found in the following paragraphs.
No Need to Install, Use Docker
OpenVINO has a couple of dependencies which need to be present on your computer. Additionally, to install some of them, you need to have root/admin rights. This might not be desirable. Using Docker represents much cleaner way. Especially when there is an image prepared for you on Docker Hub.
If you are not familiar with Docker, it might seem like a complicated piece of software, but we highly recommend you to try it and learn the basics. It is not hard and worth the effort. Docker is an important part of today’s SW development world. You will find installation instructions here.
Running the Docker Image
Containers are stateless. That means that next time you start your container, all the changes made will be gone. (Yes, this is a feature.) If you want to persist some files, just prepare a directory on your filesystem and we will bind it as a shared volume to a running container. (To /home/openvino
We will run our container in interactive mode (-it--rm
docker run -it --rm -v __YOUR_DIRECTORY__:/home/openvino openvino/ubuntu18_dev:latestTo be able to use all the tools, OpenVINO environment needs to be initialized. For some reason, this is not done automatically. (At least not for a normal user, if you start docker as a root, -u 0, setup script is run.)
source /opt/intel/openvino/bin/setupvars.shConformation is then printed out.
[setupvars.sh] OpenVINO environment initializedTensorFlow 2 Dependencies
TensorFlow 2 is not present inside the container by default. We could very easily create our own image based on the original one with TensorFlow 2 installed. This is the best way in production. With this being said, we will show you another way using the original container and installing the missing packages to an virtual environment into the shared directory (volume). This way, we can create as many such environments as we want. Or easily modify this environment. In addition, we will be still able to try the older TensorFlow 1 models. We prefer this approach during initial development.
Following code needs to be executed only once, after you first start your container.
mkdir ~/env
python3 -m venv ~/env/tensorflow2 --system-site-packages
source ~/env/tensorflow2/bin/activate
pip3 install --upgrade pip
pip3 install -r /opt/intel/openvino/deployment_tools/model_optimizer/requirements_tf2.txtWhen you close your container and open it again, this is the only part you will need to repeat.
source ~/env/tensorflow2/bin/activateConverting TensorFlow SavedModel
Let’s say you have a trained model in SavedFormat. For the sake of this tutorial, we can take a pretrained MobileNet. Execute python3
import tensorflow as tf
model = tf.keras.applications.MobileNetV2(input_shape=(224,224,3))
model.save("/home/openvino/models/tf2")Conversion is a matter of one command. However, there are few important parameters we need to use and which will be described below. Complete list can be found in the documentation. Exit python interpreter and run following command in a bash.
/opt/intel/openvino/deployment_tools/model_optimizer/mo_tf.py --saved_model_dir ~/models/tf2 --output_dir ~/models/converted --batch 1 --reverse_input_channels --mean_values [127.5,127.5,127.5] --scale_values [127.5,127.5,127.5]--batch 1--reverse_input_channels--mean_values [127.5,127.5,127.5] --scale_values [127.5,127.5,127.5]
Be careful, if you use pretrained models, different preprocessing and channel order can be used. If you try to use a neural network with input preprocessed in wrong way, you will of course get the wrong result.
You don’t need to include the preprocessing inside the converted model. The other option is to preprocess every image inside your own code before passing it to converted model. However, we use some OpenVINO inference tool which expects correct input.
At this point, we also need to mentioned that you might get slightly different values from SavedModel in TensorFlow and converted OpenVINO model. But from my experience on classification models, the difference is quite similar as when you use different ways to downscale your image to a proper input size.
Run Inference on Converted Model
First, we will get a testing picture which belongs to one of the 1000 ImageNet classes. We chose zebra, class index 340. (For TensorFlow, Google keeps the class indexes here.)

Let’s download it to our home directory We saved the small version of the image on our server so you can get it from there.
curl -o ~/zebra.jpg -s https://images.ximilar.com/tutorials/openvino/zebra.jpgThere is a script you can use for testing the prediction with no need to write any code.
python3 /opt/intel/openvino/deployment_tools/inference_engine/samples/python/classification_sample_async/classification_sample_async.py -i ~/zebra.jpg -m ~/models/converted/saved_model.xml -d CPUWe get some info lines and top 10 results at the end. Since the numbers are pretty clear, we will show only the first three.
classid probability
------- -----------
340 0.9556126
396 0.0032325
721 0.0008250Cool, our model is really sure about what is on the picture!
Using OpenVINO Inference in Python
That was easy, right? But you probably need to run the inference inside your own Python code. You can take a look inside the script. It is pretty straightforward, but for the sake of completeness, we will copy some of the code here. We will also add a code for running an inference on the original model so that you can compare it easily. If you please, run python3
We need one basic import from OpenVINO inference engine. Also, OpenCV and NumPy are needed for opening and preprocessing the image. If you prefer, TensorFlow could be used here as well of course. But since it is not needed for running the inference at all, we will not use it.
import cv2
import numpy as np
from openvino.inference_engine import IECoreAs for the preprocessing, part of it is already present inside the converted model (scaling, changing mean, inverting input channels width and height), but that is not all. We need to make sure the image has a proper size (224 pixels both sides) and the dimensions are correct – batch, channel, width, height.
img = cv2.imread("/home/openvino/zebra.jpg")
img = cv2.resize(img, (224, 224))
img = np.expand_dims(img, 0)
img_openvino = img.transpose((0,3, 1, 2))Now, we can try a simple OpenVINO prediction. We will use one synchronous request.
ie = IECore()
net = ie.read_network(model="/home/openvino/models/converted/saved_model.xml", weights="/home/openvino/models/converted/saved_model.bin")
input_name = next(iter(net.input_info))
output_name = next(iter(net.outputs))
net.batch_size = 1
# number of request can be specified by parameter num_requests, default 1
exec_net = ie.load_network(network=net, device_name="CPU")
# we have one request only, see num_requests above
request = exec_net.requests[0]
# infer() waits for the result
# for asynchronous processing check async_infer() and wait()
request.infer({input_name: img_openvino})
# read the result
prediction_openvino_blob = request.output_blobs[output_name]
prediction_openvino = prediction_openvino_blob.bufferOur result, prediction_openvino
ids = np.argsort(prediction_openvino)[0][::-1][:3]
probabilities = np.sort(prediction_openvino)[0][::-1][:3]
for id, prob in zip(ids, probabilities):
print(f"{id}\t{prob}")We get exactly the same results as before. Our code works!
Comparing Results with Original TensorFlow Model
Now, let’s do the same with TensorFlow model. Do not forget to preprocess the image first. Prepared function preprocess_input can be used for that.
import tensorflow as tf
img_tf = tf.keras.applications.mobilenet_v2.preprocess_input(img)
model = tf.keras.models.load_model("/home/openvino/models/tf2")
prediction_tf = model.predict(img_tf)The results are almost the same, the difference is so small that we can ignore it. The top result from this prediction has probability 0.95860416, compared to 0.9556126 we had before. The order of the other predictions might be slightly different, because the values are so tiny.
By the way, there is a build-in function decode_predictions, which will not only give you the top results, but also class names and codes instead of just ids. Top 3 TensorFlow predictions.
from tensorflow.keras.applications.mobilenet_v2 import decode_predictions
top3 = decode_predictions(prediction_tf, top=3)Here is the result:
[[('n02391049', 'zebra', 0.95860416), ('n02643566', 'lionfish', 0.0032956717), ('n01968897', 'chambered_nautilus', 0.0008273276)]]Benchmarking
We should mention that there is also a tool for benchmarking OpenVINO models called Benchmark Python Tool. It offers synchronous (latency-oriented) and asynchronous (throughput-oriented) measuring modes. Unfortunately, it does not work for other models (like TensorFlow) and cannot be used for direct comparison.
How OpenVINO Helped Us
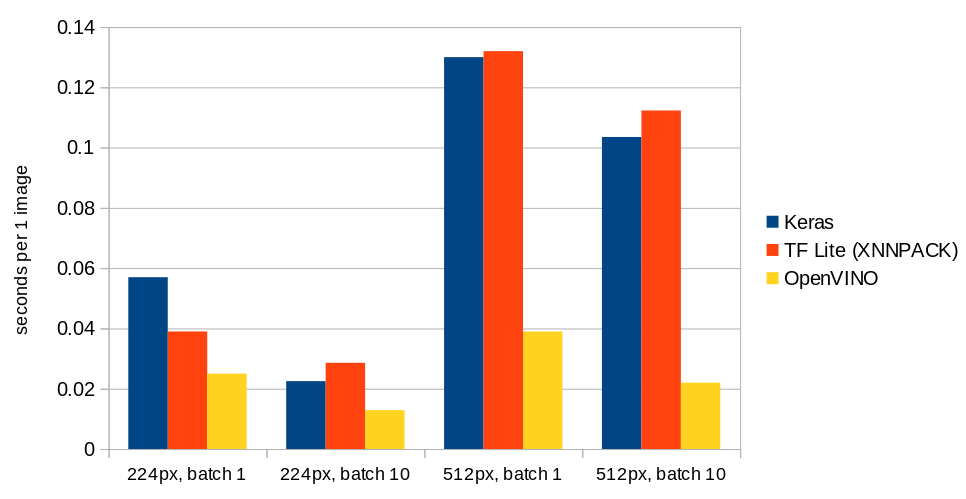
Enough of code, at the end of the article we will add some numbers. In Ximilar, we use often recognition models with resolution of 224 or 512 pixels. In a batch of 1 or 10. We used TensorFlow Lite format as often as possible, because it is very fast to load. (See a comparison here.) Because of a fast loading, it is not necessary to have the model in the cache all the time. To make running TF Lite models faster, we enhance the performance with XNNPACK.
Below you can see a chart with results for MobileNet V2. For the batches, we show prediction time in seconds per single image. Tests were done on our production workers.
Summary
In this article, we briefly introduced some of the basic functionality of OpenVINO. Of course, there is much more to try. We hope that this article has motivated you to try it yourself and maybe continue to explore all the possibilities through more advanced resources.

Libor Vanek
Libor is an skilled machine learning developer with extensive experience in the fields of artificial intelligence and computer vision. He helped us build many innovative solutions and moved on to more specialized projects in OCR and LLM.
Tags & Themes
Related Articles
Vision Language Model Evaluation & Inspection Made Easy
From loss curves to GGUF exports – mastering your vision language model evaluation workflow with built-in metrics.
Fine-Tuning a Vision Language Model With the Ximilar API
Fine-tune your vision-language model with image understanding, run it on your own hardware, and cut your per-inference token costs.
How to Fine-Tune a Vision Language Model Without Writing Code
Ximilar’s no-code VLM platform lets you fine-tune small, private AI models and deploy them on any device – no ML expertise required.