Ximilar not only grows by its customer base, but we constantly learn and add new features. We aim to give you as much comfort as possible — by delivering great user experience and even features that might not have been invented yet. We learn from the AI universe, and we contribute to it in return. Let’s see the feature set added in the early spring of 2019.
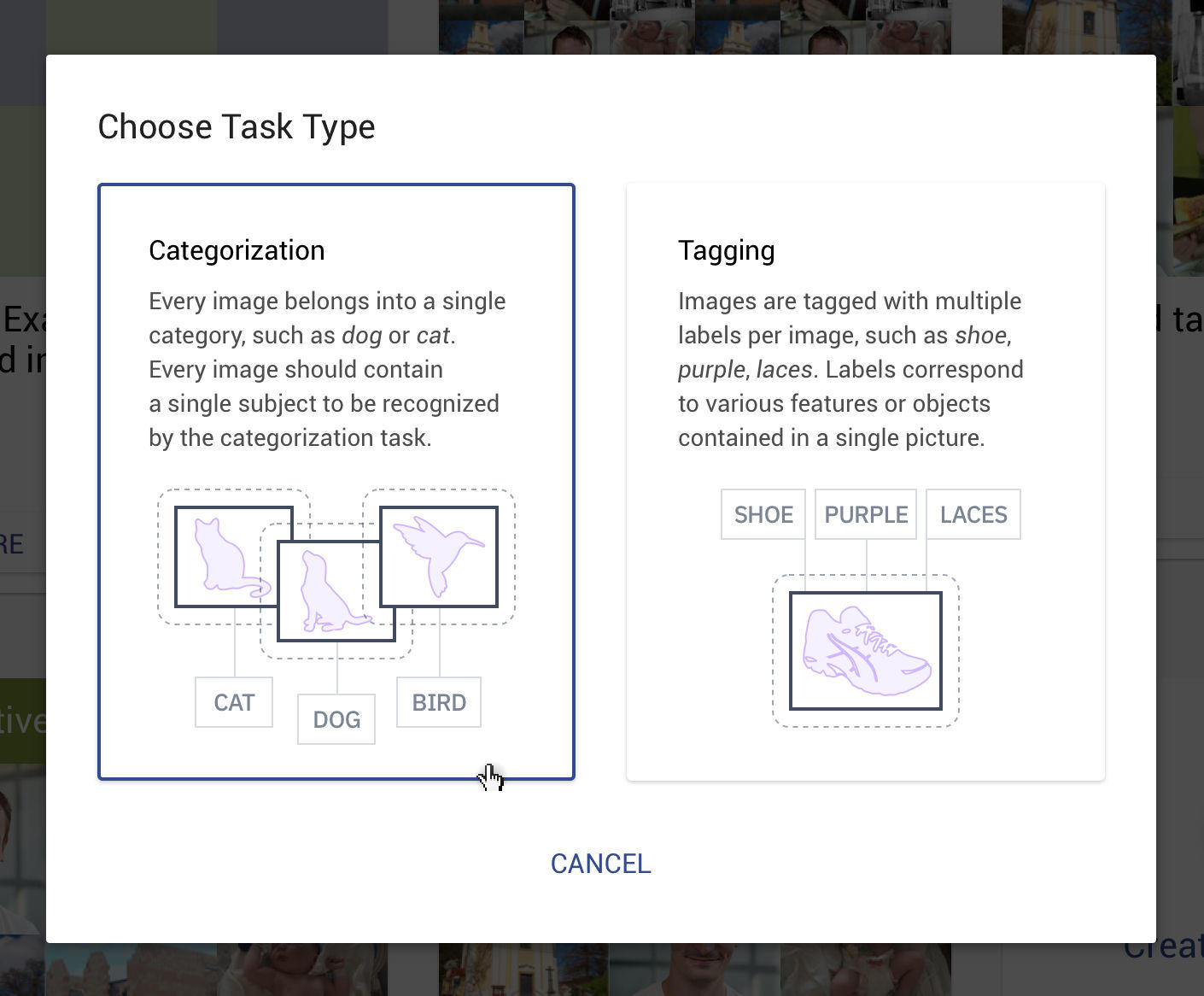
New Label Types: Categories & Tags
This one is a major, long-awaited upgrade, to our custom recognition system.
Until this point, we offered only image categorization,
formally: multi-class classification, where every image belongs to exactly one category. That was great for many use cases, but some elaborate ones needed more. So now we introduce
Tagging tasks,
formally: multi-label classification, where images are tagged with multiple labels per image. Labels correspond to various features or objects contained in a single picture. Therefore, from this point on, we use strictly
categorization or
tagging, and not
classification anymore.
With this change, the
Ximilar App starts to differentiate two kinds of labels —
Categories and
Tags, where each image could be assigned either to one
Category or/and multiple
Tags.
For every Tagging Task that you create, the Ximilar App automatically creates a special tag “<name of the task> – no tags” where you can put images that contain none of the tags connected to the task. You need to carefully choose the type of task when creating, as the type cannot be changed later. Other than that, you can work in the same way with both types of tasks.
When you want to categorize your images in production, you simply take the category with the highest probability – this is clear. In the case of tagging, you must set a threshold and take tags with probability over this threshold. A general rule of thumb is to take all tags with a probability over 50 %, but you can tune this number to fit your use case and data.
With these new features, there are also a few minor API improvements. To keep everything backwards compatible, when you create a
Task or
Label and do not specify the type, then you create a
Categorization task with
Categories. If you want to learn more about our REST API, which allows you to manage almost everything even training of the models, please check out
docs.ximilar.com.
Benefit: Linking Tags with Categories
So hey, we have two types of labels in place. Let’s see what that brings in real use. The typical use-case of our customers is, that they have two or more tasks, defined in the same field/area. For instance, they want to enhance real-estate properties so they need:
- Automatically categorize photos by room type — living room, bedroom, kitchen, outdoor house. At the same time, also:
- Recognize different features/objects in the images — bed, cabinet, wooden floor, lamp, etc.
So far, customers had to upload — often the same — training images separately into each label.
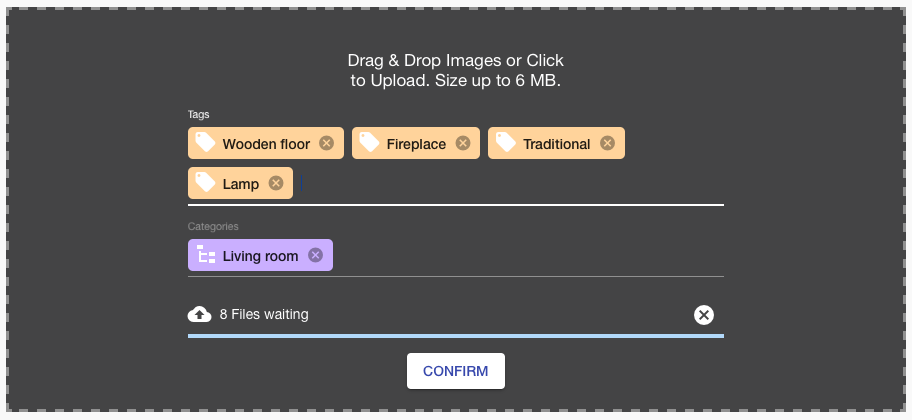
This upgrade makes this way easier. The new Ximilar App section Images allows you to upload images once and assign them to several Categories and Tags. You can easily modify the categories and tags of each image there. Either one by one or in bulk. There can be thousands of images in your workspace. So you can also filter images by their tags/categories and do batch processing on selected images. We believe that this will speed up the workflow of building reliable data for your tasks.
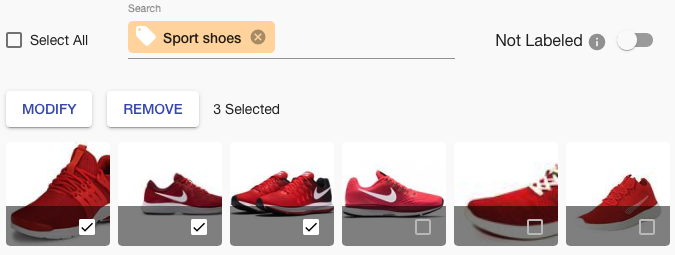
Improved Search
Some of our customers have hundreds of Labels. With a growing number of projects, it started to be hard to orient all Labels, Tags, and Tasks. That is why there is now a search bar at the top of the screen, which helps you find desired items faster.
Updated Insights
As we mentioned in our
last update notes, we offer a set of insights that help you increase the quality of results over time by looking into what works and what does not in your case. In order to improve the accuracy of your models, you may inspect the details of your model. Please see the
article on Confusion Matrix and Failed Images insights and also another one, talking about the
Precision/Recall table. We have recently updated the list of
Failed images so that you can modify the categories/tags of these failed images — or delete them — directly.
Upcoming Features
- Workspaces — to clearly split work in different areas
- Rich statistics — number of API calls, amount of credits, per task, long-term/per-month/within-week/hourly and more.
We at Ximilar are constantly working on new features, refactoring the older ones and listening to your requests and ideas as we aim to deliver a great service not just out of the box, and not only with pre-defined packages but actually meeting your needs in real-world applications. You can always write to us at and request some new API features which will benefit everyone who uses this platform. We will be glad if you share with us how do you use the Ximilar Recognition in your use cases. Not only this will help us grow as a company, but it will also inspire others.
We create the Ximilar App as a solid entry point to learn a bunch about AI, but our skills are mostly benefiting custom use cases, where we deliver solutions for Narrow Fields AI Challenges, that are required more than a little over-hyped generic tools that just tell you this is a banana and that is an apple.