Explainable AI: What is My Image Recognition Model Looking At?
With the AI Explainability in Ximilar App, you can see which parts of your images are the most important to your image recognition models.


There are many challenges in machine learning, and developing a good model is one of them. Even though neural networks are very powerful, they have a great weakness. Their complexity makes it hard to understand how they reach their decisions. This might be a problem when you want to move from development to production, and it might eventually cause your whole project to fail. But how can you measure the success of a machine learning model? The answer is not easy. In our opinion, the model must excel in a production environment and should work reliably in both common and uncommon situations.
However, even when the results in production are good, there are areas, where we can’t simply accept black box decisions without being sure, how the AI made them. These areas are typically medicine and biotech or any other field where there is no place for errors. We need to make sure that both output and the way our model reached its decision make sense – we need explainable AI. For these reasons, we introduced a new feature to our Image Recognition service called Explain.
Training Image Recognition
Image Recognition is a Visual AI service enabling you to train custom models to recognize images or objects in them. In Ximilar App, you can use Categorization & Tagging and Object Detection, which can be combined with Flows. For example, the first task will detect all the human models in the image and the categorization & tagging tasks will categorize and tag their clothes and accessories.
Image recognition is a very powerful technology, bringing automation to many industries. It requires well-trained models, and, in the case of object detection, precise data annotation. If you are not familiar with using image recognition on our platform, please try to set up your own classifier first.
These resources should be helpful in the beginning:
- Check the Custom Image Recognition page
- Read The Basic Rules for Image Recognition Models Training
- Read Best Practices in Image Recognition Training
- Watch our YouTube tutorial on how to set up the image recognition task
- Read how to combine and chain your models with Flows
From model-centric to data-centric with explainable AI
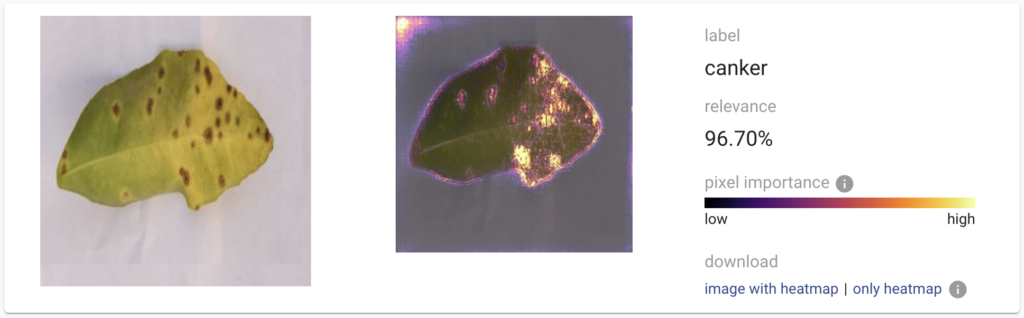
When you want a model which performs great in a production setting and has high accuracy, you need to focus on your training data first. Consistency of labelling, cleaning datasets from unnecessary samples/labels, and adding feature-rich samples that are missing is much more important than the newest architecture of the neural network. Andrew Ng, an entrepreneur and professor at Stanford, is also promoting this approach to building machine learning models.
The Explain feature in our App tells you:
- which parts of images (features and pixels) are important for predicting specific labels
- for which images the model will probably predict the wrong results
- which samples should be added to your training dataset to improve performance
Simple Example: T-shirt or Not?
Let’s look at this simple example of how explainable AI can be useful. Let’s say we have a task containing two categories – t-shirts and shoes. For a start, we have 20 images in each category. It is definitely not enough for production, but it is enough if you want to experiment and learn.
After playing with the advanced options and short training, the result seems really promising:

Using Explain on a Training Image
But did the model actually learn what we wanted? To check, what the neural network find important when categorizing our images, we will apply two different methods with the tool Explain:
- Grad-CAM (first published in 2016) – this method is very fast, but the results are not very precise
- Blur Integrated Gradients (published in 2020) smoothed with SmoothGrad – this method provides much more details, but at the cost of computational time


In this case, both methods clearly demonstrate the problem of our model. The focus is not on the t-shirt itself, but on the head of the person wearing it. In the end, it was easier for the learning algorithm and the neural network to distinguish between the two categories using this feature instead of focusing on the t-shirt. If we look at the training data for label t-shirt, we can see that all pictures include a person with a visible face.
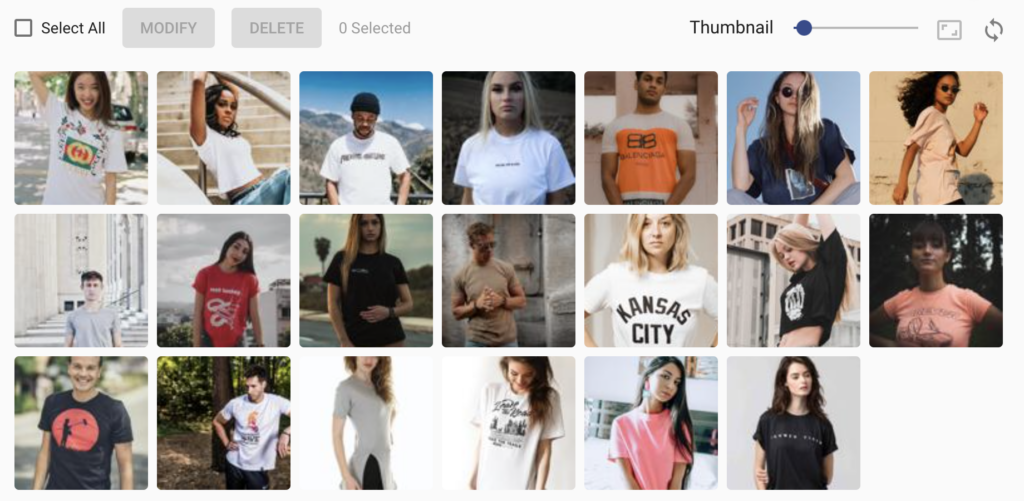
Explainability After Adding New Data
The solution might be adding more varied training data and introducing images without a person. Generally, it’s a good approach to start with a small dataset and over time increase it to a bigger one. Adding visually broad images helps model with overfitting on wrong features. So we added more photos to the label and trained the model again. Let’s see what the results look like with our new version of the model:

The Grad-CAM result on the left is not very convincing in this case. The image on the right shows the result of Blur Integrated Gradients. Here you can see, how the focus moved from the head to the t-shirt. It seems like the head still plays some part, but there is much less focus on it.
Both methods for explainable AI have their drawbacks, and sometimes we have to try more pictures to get a better understanding of model behaviour. We also need to mention one important point. Due to the way the algorithm works, it tends to prefer edges, which is clearly visible in the examples.
Summary
The Explainability and Interpretability of Neural Networks is a big research topic, and we are looking forward to adopting and integrating more techniques into our SaaS AI solution. AI Explainability that we showed you is only one tool amongst many towards data-centric AI.
If you have any troubles, do not hesitate to contact us. The machine learning specialists of Ximilar have vast experience with different kinds of problems, and are always happy to help you with yours.

Zuzana Raidová
Head of Marketing
Zuzana is a marketing specialist, biologist, and illustrator addicted to reading and hiking. At Ximilar, she takes care of web content and communication, tries to keep the articles engaging, and the office temperature low. She likes science, kung fu movies, and rain.
Tags & Themes
Related Articles

The Ultimate Guide to LLM Fine-Tuning Platforms and Tools
The best LLM fine-tuning platforms and tools, from training and deployment to inspecting custom language models.
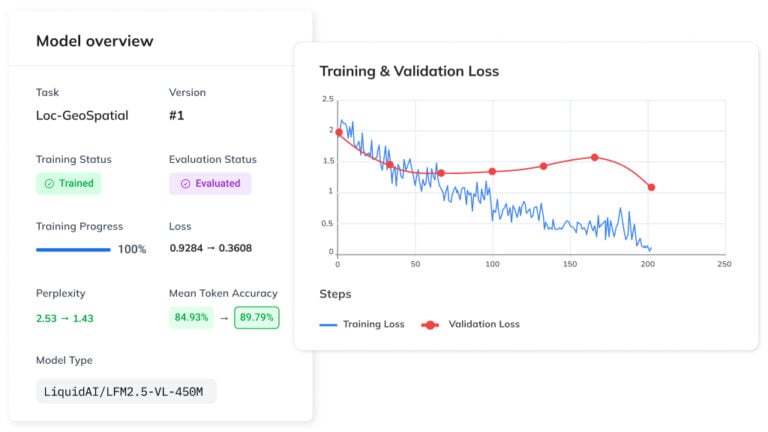
Vision Language Model Evaluation & Inspection Made Easy
From loss curves to GGUF exports – mastering your vision language model evaluation workflow with built-in metrics.
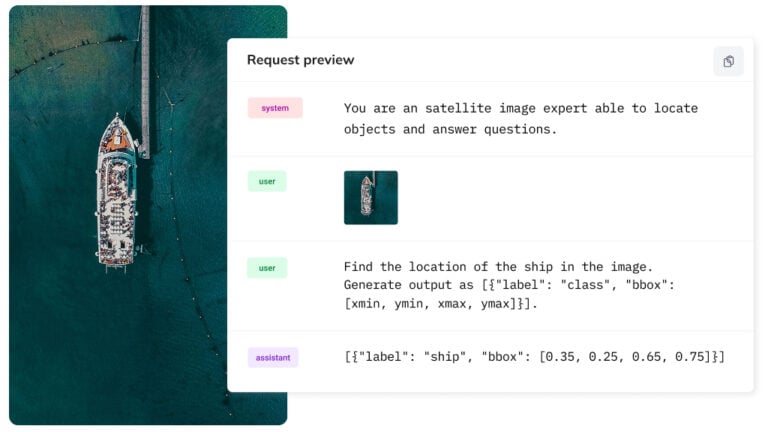
Fine-Tuning a Vision Language Model With the Ximilar API
Fine-tune your vision-language model with image understanding, run it on your own hardware, and cut your per-inference token costs.