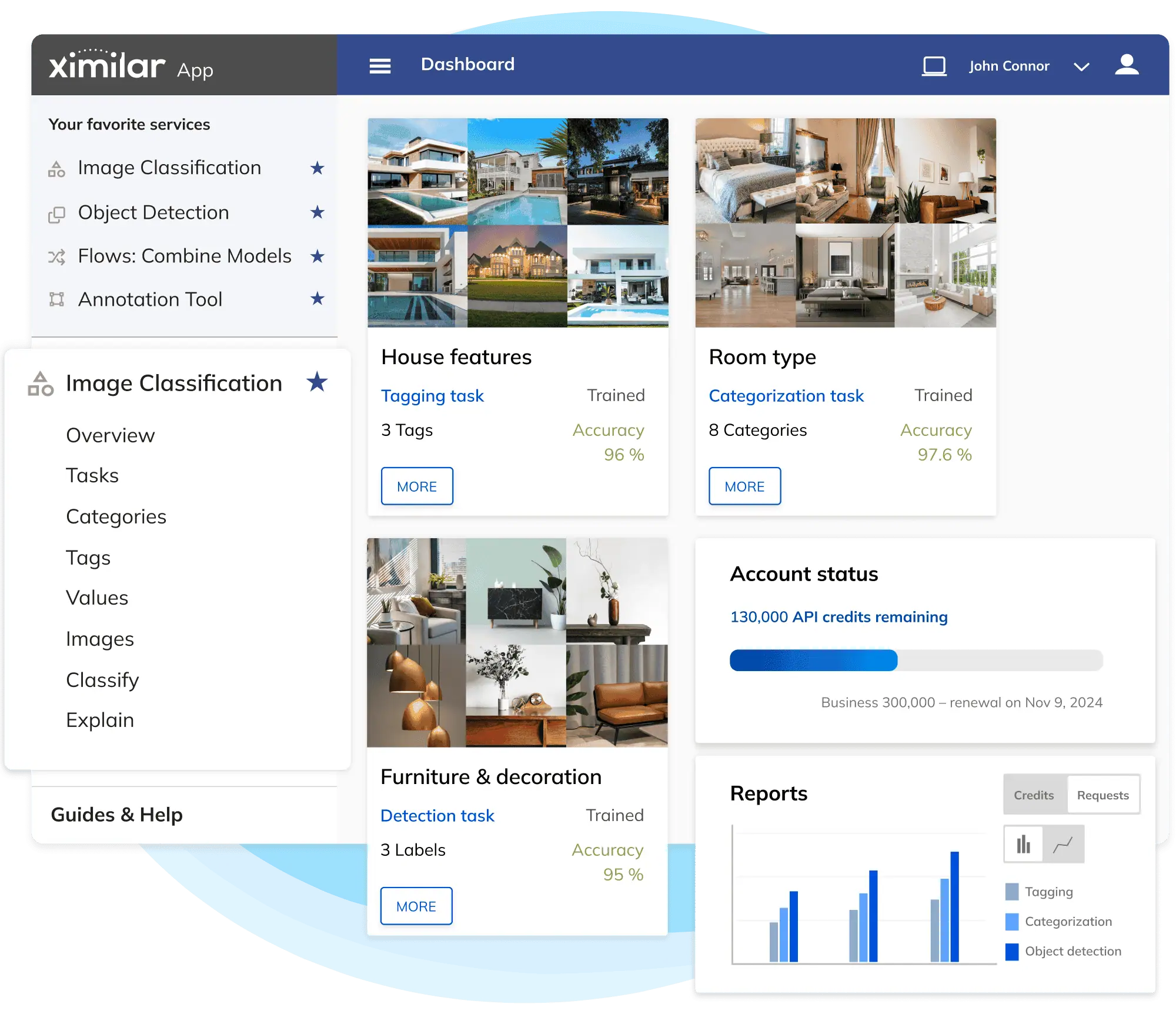
Recognize, Search & Enhance Images With AI
Get Custom AI Tailored to Your Images
Build Computer Vision Models Without Coding
Ready-to-use Visual AI
Learn moreCustom AI Solutions
Learn moreComputer Vision Platform
Learn more

Ready-to-use Visual AI demos
Test Our Visual AI
Choose from off-the-shelf solutions for fashion, home decor, stock photos, collectibles, and more.
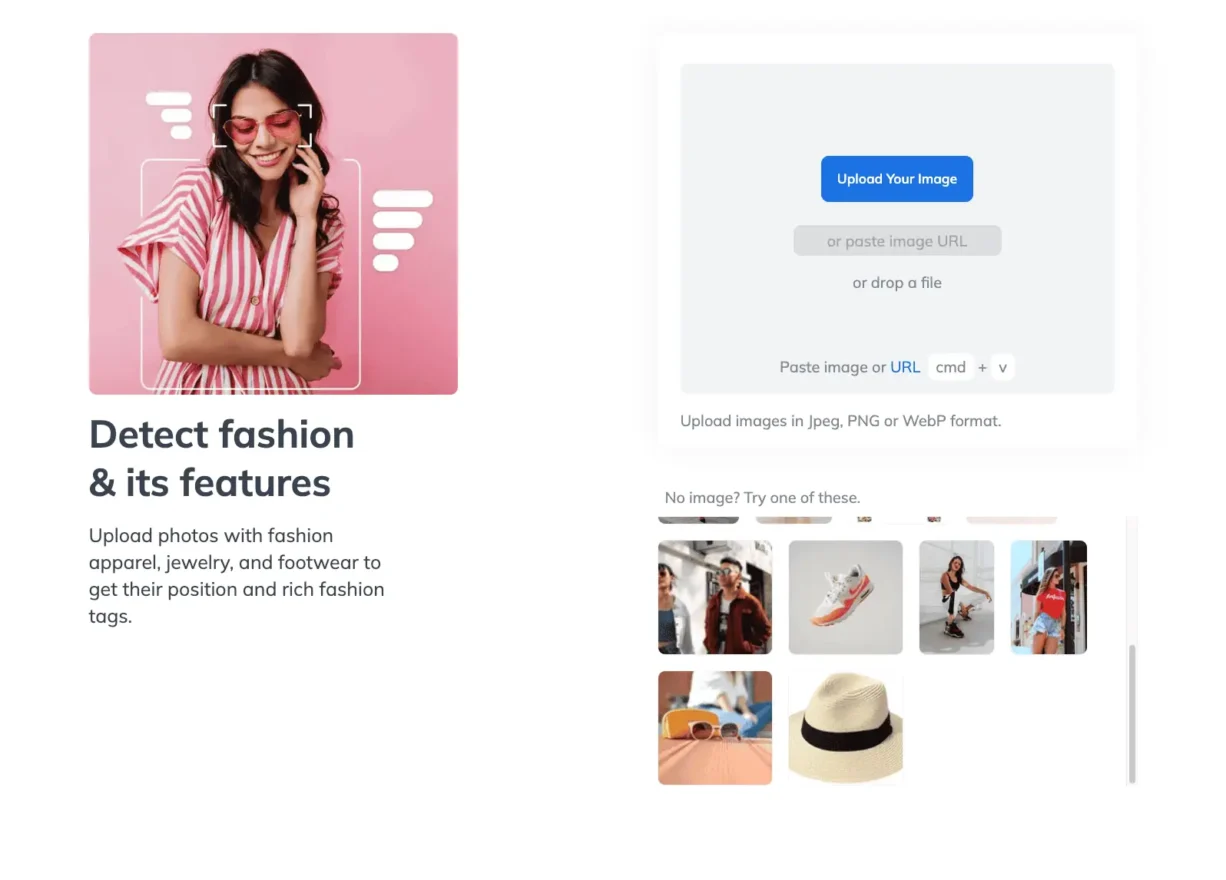 Click to Load Demo
Click to Load Demo
FROM PATTERN RECOGNITION TO IMAGE SIMILARITY
Get Custom AI Tailored to Your Visual Data
Custom features — Your own labels, object categories, attributes, taxonomy, or language can be added to our solutions.
Semi-custom solutions — We can combine pre-trained & new modules for a tailored, budget-friendly solution.
New solutions for pioneers — We will craft an image or video processing system from scratch to help you pave the way.
Custom features — Your own labels, object categories, attributes, taxonomy, or language can be added to our solutions.

Semi-custom solutions — We can combine pre-trained & new modules for a tailored, budget-friendly solution.

New solutions for pioneers — We will craft an image or video processing system from scratch to help you pave the way.
MACHINE LEARNING FOR EVERYONE
No-Code Computer Vision Platform
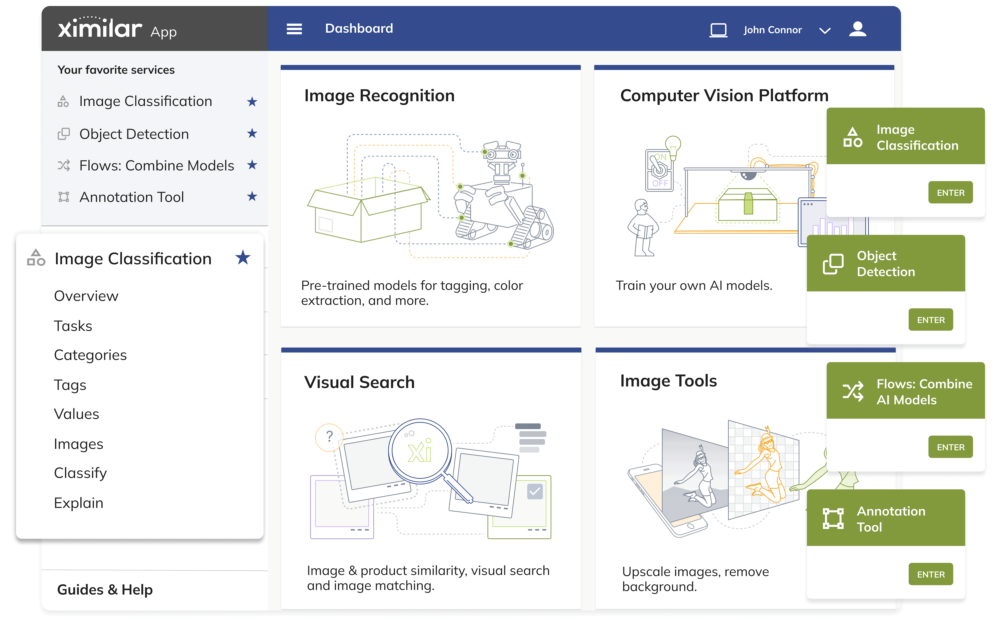
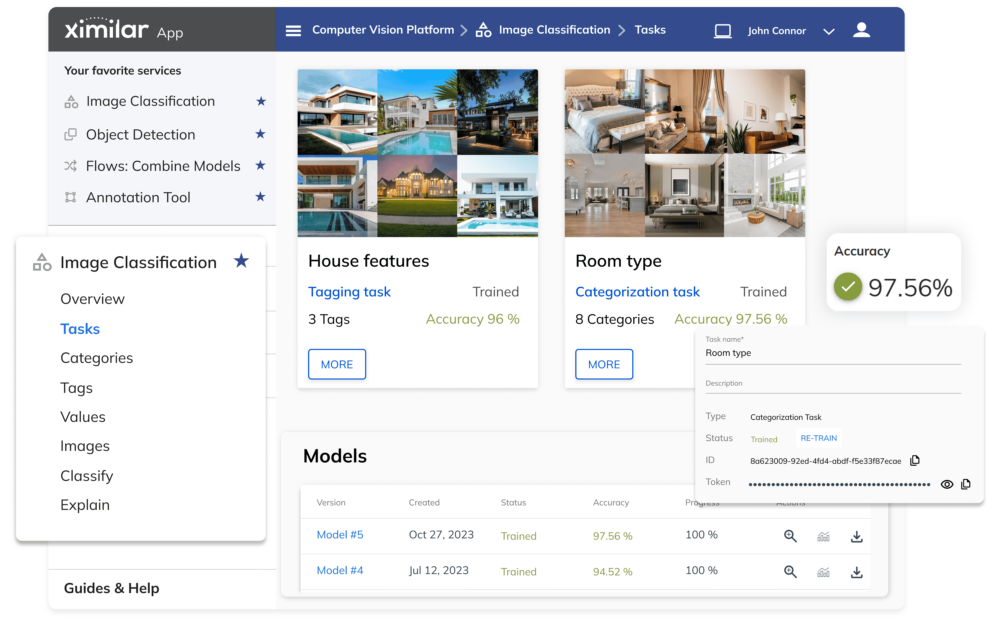
NUMBER 1 NO-CODE AI VISION PLATFORM
All-in-one Suite for Visual Data
With Ximilar, you can automate & streamline all image processing with one API. All on one platform and without coding.
TIME-EFFICIENT
Save work & time
Deploy the pre-trained tools on click, or add custom labels and features.
MONTHLY SUBSCRIPTION
Choose ideal plan
EASY ACCESS
Connect via API
And implement it into your application, website or infrastructure.
MODULAR STRUCTURE
Upgrade on the go
Workflow examples

Sports & Trading Cards Identification
Spot, analyze and grade collectible sports cards and trading card games (TCGs) automatically.

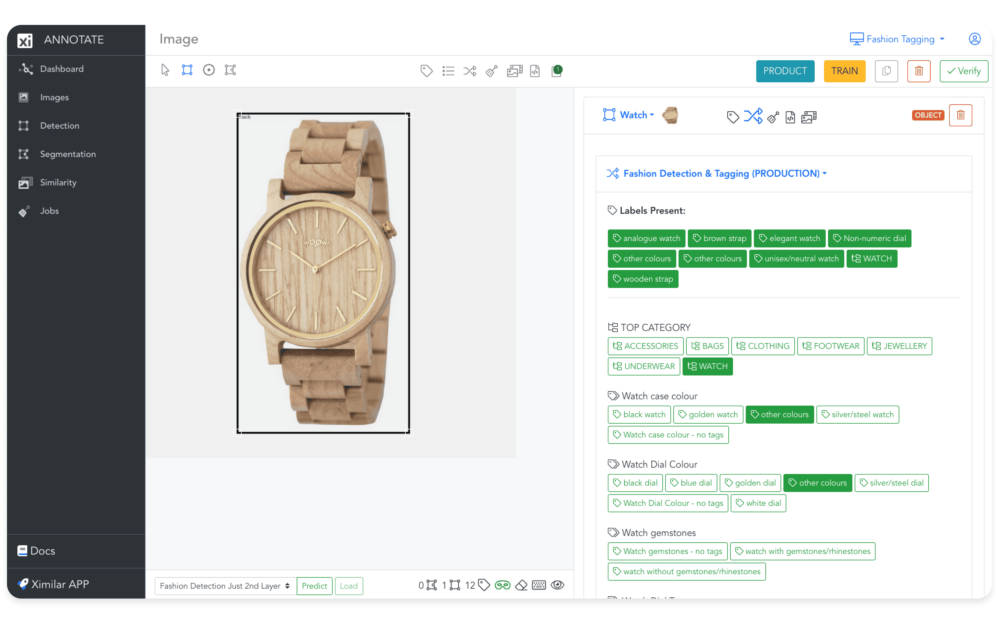
Fashion Detection, Tagging & Description
Identify all fashion including footwear and jewelry with specialized clothing AI. Generate product titles and descriptions.

Stock Photo Tagging & Similarity Search
Accurately identify photos, people, faces & objects. Provide similar visual content within your collection to your visitors.

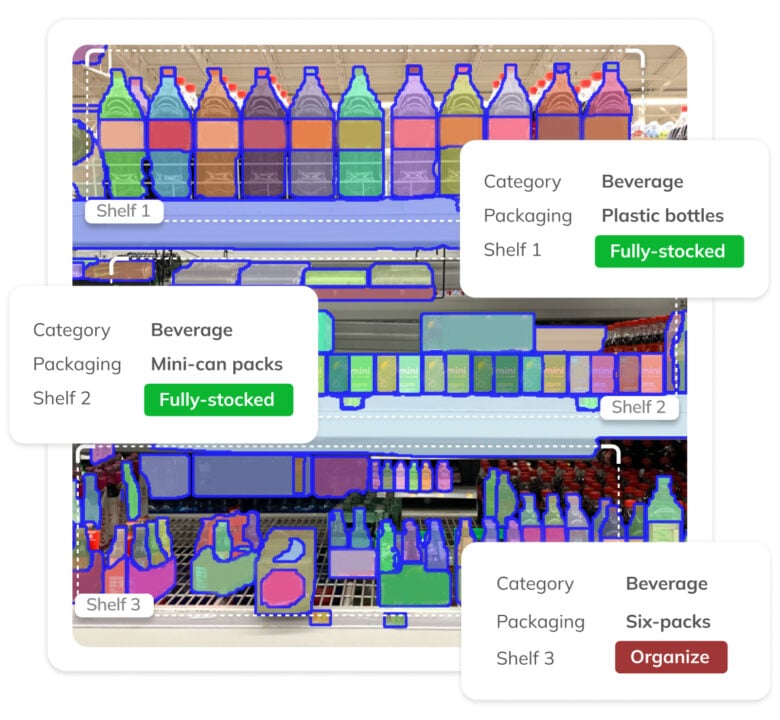
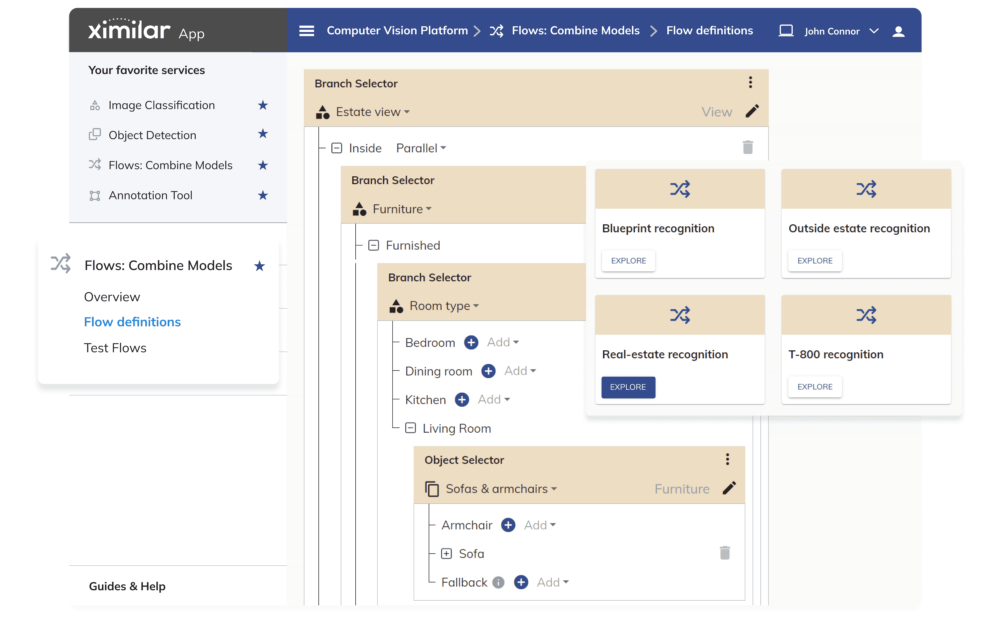
Real Estate Classifier
Automate the processing of photos of real estate, rooms, interior design, homeware, and pieces of furniture.
HUMAN EXPERTISE, AI CONSISTENCY
Get Your AI Solution From Industry Experts
15 Billion
Images recognized and counting
+380 %
Increased click rate on products
40+
Countries of origin of our clients
10+ Years
Hands-on experience in AI systems





15 Billion
Images recognized and counting
+380 %
Increased click rate on products
40+
Countries of origin of our clients
10+ Years
Hands-on experience in AI systems
USE AI WITH CONFIDENCE
Transparency & Security Come First






We used Ximilar’s platform to build a model analyzing X-ray medical images. Even though the models are built on their platform, the data belong to our company. Support from Ximilar has been amazing, with a response time less than 24 hours. Overall, I am extremely happy with the service and product offerings from Ximilar.
Dr. Reza Farshey
Founder & CEO

Ximilar has been a fantastic partner for our card recognition needs. The backend system is highly reliable, and in the time we’ve been with Ximilar, we haven’t encountered a single issue. The team is incredibly responsive, always quick to address any queries we’ve had, and they consistently go above and beyond to ensure we fully understand and utilize their services. Their commitment to support and seamless performance earns them a well-deserved 5 stars. Highly recommended!
Damo Bowland
CEO

Babyndex uses Ximilar’s Image Recognition and Annotate, which is excellent. I can easily set up their services myself. Ximilar has helped in improving accuracy and from that day on, it works perfectly.
Zajzon Bodó
Co-founder & CEO, Babyndex

We integrate Ximilar’s visual AI into our online product discovery tool. With Ximilar’s visual search, we can tailor recommendations of newly arrived products to customers who are likely to be interested. Our system automatically notifies them, enhancing the overall customer experience. Our experience with Ximilar has been great.
Filiberto Sosa
CEO


Way better similar results in our 10 million stock images. Customers can find visually similar pictures by uploading a photo. The integration was fast. We recommend it!
Amos Struck
Co-founder

The Ximilar technology has been working reliably for many years on our collection of 100M+ creative photos.
Pavel Macků
CEO
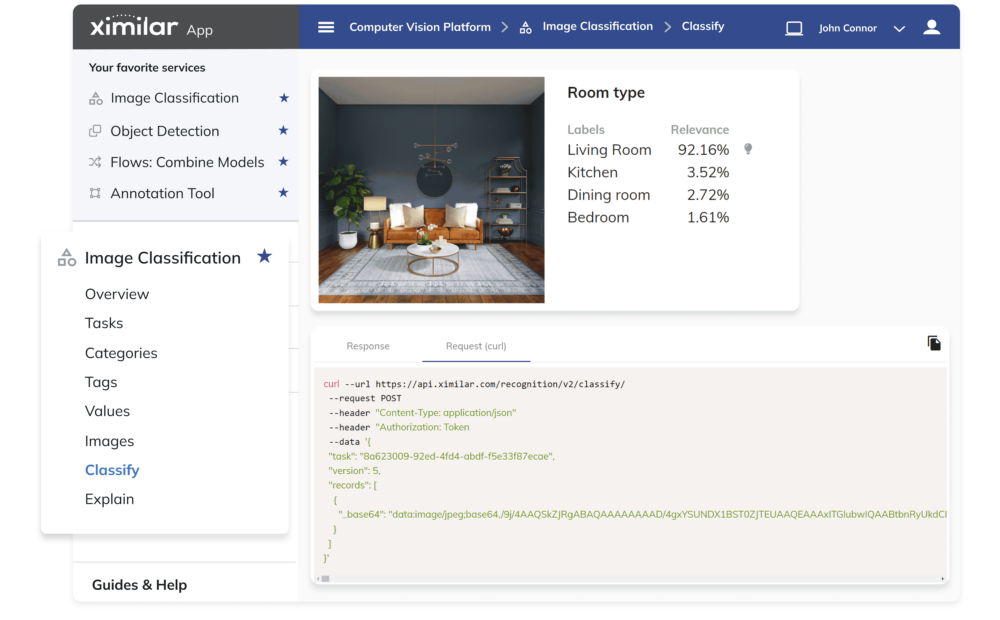
CONNECT VIA REST API
Deploy, Connect & Conquer
Deploy latest models on click, connect via REST API, and integrate them into your system or infrastructure.
Technology Stack
# pip install ximilar-client
import base64
from ximilar.client import FashionTaggingClient
with open(__IMAGE_PATH__, "rb") as image_file:
encoded_string =
base64.b64encode(image_file.read()).decode('utf
-8')
client = FashionTaggingClient("__API_TOKEN__")
response = client.detect_tags([{'_base64': encoded_string}])import requests, json, base64
endpoint = 'https://api.ximilar.com/tagging/
fashion/v2/detect_tags'
headers = {
'Authorization': "Token __API_TOKEN__",
'Content-Type': 'application/json'
}
with open(__IMAGE_PATH__, "rb") as image_file:
encoded_string =
base64.b64encode(image_file.read()).decode('utf
-8')
data = {
'records': [{'_base64': encoded_string}]
}
response = requests.post(endpoint,
headers=headers, data=json.dumps(data)).json()$curl_handle = curl_init("https://
api.ximilar.com/tagging/fashion/v2/
detect_tags");
$data = ['records' => [ [ '_url' =>
'__PATH_TO_URL_IMAGE__' ], [ '_base64' =>
base64_encode(file_get_contents(__PATH_TO_IMAGE
__)) ] ] ];
curl_setopt($curl_handle,
CURLOPT_CUSTOMREQUEST, "POST");
curl_setopt($curl_handle, CURLOPT_POSTFIELDS,
json_encode($data));
curl_setopt($curl_handle,
CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl_handle, CURLOPT_FAILONERROR,
true);
curl_setopt($curl_handle, CURLOPT_HTTPHEADER,
array( "Content-Type: application/json",
"Authorization: Token __API_TOKEN__", "cache-
control: no-cache",) );
$response = curl_exec($curl_handle);
$error_msg = curl_error($curl_handle);
curl_close ($curl_handle);curl --request POST \
--url https://api.ximilar.com/tagging/
fashion/v2/detect_tags \
--header 'Content-Type: application/json' \
--header 'authorization: Token __API_TOKEN__'
\
--data '{"records":[{"_url": "https://
bit.ly/2IymQJv"}]}'Frequently Asked Questions
How image recognition works?
Image recognition allows computers to understand and classify images by analyzing their content. It helps with interpreting, tagging (enrichment with additional metadata), or categorization (sorting into groups) of images.
For example, if you train a dog vs. cat recognition model, and provide it with a folder of mixed pictures, it will be able to distinguish between cats and dogs, and thus sort the images into two separate folders.
It is used in various applications including medical diagnosis, autonomous vehicle systems (object recognition) or security systems (like facial recognition). The accuracy, speed, and efficiency of such systems continue to improve with advancements in artificial intelligence and machine learning techniques and depend on factors such as the quality of training datasets. Deep learning algorithms, particularly convolutional neural networks (CNNs), are commonly used for image categorization tasks.
Ximilar provides several off-the-shelf solutions for classifying specific image data, such as stock photos, home decor and furniture images, fashion photos, or trading and collectible cards. Custom models can be easily trained on our platform. Read the articles in our blog to learn about image recognition technology.
What is Visual Search?
Visual & similarity search technology can analyze the overall visual aesthetic of an image or detected object in an image, independent of the origin of images or metadata (such as keywords). It understands the concept of similarity according to your subjective perception. That is why it can provide the most relevant results to image queries, whether you look for the exact match or similar items.
Go to:
Which collectibles can AI Recognition of Collectibles recognize?
As for now, the service is able to detect (and mark by bounding boxes) the collectibles such as stamps, coins, banknotes, comic books and trading cards, as well as antique items.
For collectible cards, the service can identify whether it is a Trading Card Game (Pokémon, Magic The Gathering – MTG, Yu-Gi-Oh!, Lorcana, Flesh and Blood and so on) or a Sports Card (Baseball, Basketball, Hockey, Football, Soccer, or MMA), with several additional features (e.g., signature). It can be easily customized to evaluate images based on your criteria. The full taxonomy of the identification results with all supported games and sports can be found in our documentation page.
For comic books, the service can identify more than 1 million magazines, books and manga – via name, title, publisher, issue number and release date.
The service is constantly expanding based on the requests from our customers.
Go to:
How Ximilar streamlines image processing tasks and reduces costs?
Ximilar’s systems significantly reduce image processing costs by automating repetitive tasks such as analyzing, tagging and sorting of images. This automation results in significant long-term savings, allowing for continuous 24/7 addition of new visual content without additional metadata.
We’re continually enhancing our platform, which enables us to both build services efficiently and quickly and also to modify existing solutions to suit your needs. We reduce costs and labour by utilizing a combination of pre-trained and new models.
Service use is billed via API credits, with a customizable monthly plan based on your consumption. Using our credit calculator helps you optimize cost-effectiveness. For sudden system loads, you can add extra credit packs to your monthly credit supply.
Once your solution is live, we can continually upgrade and enhance it, altering any component in the modular structure. Our feedback mechanisms help us understand which model performs best, allowing us to refine the solution. Also, our ready-to-use solutions are routinely updated to stay industry-relevant, and these upgrades come at no extra cost.
What are the typical Visual Search applications?
Visual search typically involves searching images or products using an image query, including photos from social media and user-generated content, like smartphone photos. Our Search by Photo combines this technology with detecting individual products in images. One such solution is Search Fashion by Photo.
The technology is frequently employed for similarity searches, particularly for product recommendations in e-commerce. It assesses image or detected object features, like colour, edges, or patterns, to suggest the most similar alternatives.
Another typical use is image & product matching. Since the technology can identify duplicates or nearly identical items in various images with different quality, it can help with curating product galleries and eliminating all unnecessary content.
Even though applications in e-commerce are the most common, visual search provides endless possibilities even in the industrial sector, scientific research or security systems.
:
- What are the examples of visual & similarity search solutions built by Ximilar?
- How Visual AI helps e-shops, price comparators, or collectibles’ sites?
- Can Visual AI help with sorting, filtering, and recommendations of images or products on my website?
- How to find duplicates, enrich product galleries, or add the metadata to the new images?
- How do I know if I need a custom visual search solution?
- How many images do we need to train a visual similarity model?
- Can we build a smartphone app to search for specific products?
- Can visual search engine built by Ximilar be deployed on our servers?
Is Ximilar’s visual AI able to handle large datasets and complex images?
Ximilar’s AI solutions were built to handle large datasets containing millions of images. Our cloud doesn’t physically store your image collections for visual search. We process each image once during synchronization, extract descriptive data, and then immediately discard it, allowing for swift image processing. For instance, our largest collections, holding over 100 million images, require only a few hundred milliseconds to search for visually similar items.
Complex images containing more objects, patterns, topics, people or items, can be easily processed with our AI. For instance, our Fashion Search and Home Decor Search solutions automatically detect all fashion apparel or homeware in the images, providing categories and similar stock to each object individually. You can test these solutions in our public demo.
Custom image recognition and detection solutions rely on dedicated training image datasets, whose size depends on the complexity of the problem. For instance, training a model for cat and dog recognition may only require tens of images, while larger projects like our fashion recognition, with thousands of features and tags, necessitate datasets containing thousands of images.
We also enable asynchronous requests. Read more about them in the API Documentation.
:
- Does Ximilar store my images?
- How many images can be in a visual search collection?
- How many images do we need to train a visual similarity model?
- How do we keep our visual search collection updated?
- What is the difference between synchronous and asynchronous API requests?
- My company needs a more complex solution. Can you develop it?
How does Ximilar approach privacy and data protection issues?
Ximilar prioritizes data security and confidentiality. Our customers particularly value the following rules:
- We don’t store user images, except for mutually agreed training datasets, secured on Amazon S3 with time-limited links.
- The intellectual rights to generated image models are shared between you and Ximilar, and we are not authorized to use the models for other customers or internal purposes.
- We adhere to European regulations, including GDPR, and our data center in Prague is multi ISO-certified.
- We can sign NDAs and customize image access restrictions based on your needs.
- Administrators access your image data only when necessary.
- On-premises installation is possible for larger projects.
Feel free to reach out with questions about ethical considerations regarding privacy and data protection.
Which types of images and formats does Ximilar support?
You can send images in these supported formats to our API (in fields of _base64 or _url): jpg, jpeg, png, webp, heic, bmp, tiff, and jfif. If you upload a gif, only the first frame will be processed. Contact us for customization.
Go to:
How fast and efficient is the image recognition process?
The speed typically ranges from 5 to 100 milliseconds per image for basic image classification and detection models. This timeframe varies based on factors such as input resolution, connectivity, and the speed of the image CDN used. Our platform’s models are generally very fast, and they can be fine-tuned for even greater efficiency on specialized hardware like GPUs and smartphones.