Image Similarity as a Service For Your Web
A step-by-step guide for using image similarity as a service. Find similar items with accurate & fast API for Image Search.


With the service Image Similarity added to the Ximilar App, you can build your own visual similarity engine powered by artificial intelligence in just a few clicks, with several lines of code. Similarity search enables companies to improve the user experience significantly and increase revenue with smarter management of their visual data.
The technology behind image similarity is robust, reliable & fast. Built on state-of-the-art (SOTA) AI models and vector databases, you can search millions of images/products in milliseconds. It is used by big e-commerce players as well as small startups for showing visual alternatives or finding products with pictures. Some of our customers have hundreds of millions of images in their collections and do more than 100 million requests per month. Let’s dive into building a superfast similarity search service for your web.
What is Image Similarity?
Image Similarity, or image similarity search, is a visual AI service comparing, grouping, and recommending visually similar images. For example, a typical use case is a product recommendation of similar items in e-shops. It can also be used for reverse image search, where the query is an external image and the results are images from the collection. This approach gives way more accurate results than searching by tags, labels and other attributes.
Ximilar is using state-of-the-art deep learning models for all visual search services. We build our own indexing & searching technology that can run both as a service or on your hardware if needed. The collections can be focused either on product photos, fashion, image matching, or generic photos (stock images).
Features of the Image Similarity Service
Here are several features of the Image Similarity service that we think are crucial:
- Simple access through the Ximilar App (creating a collection on click) and connection to REST API
- The scalable search service can handle collections with hundreds of millions of similar items (images, videos, etc.) and hundreds of requests per second with both CRUD operations and searching
- The ultra-fast and reliable engine that is mostly deployed in large e-commerce platforms – the query for finding the most visually similar product is low latency (in milliseconds)
- The service is customizable – the platform enables you to train your own model for visual similarity search
- Advanced filtering that supports JSON meta-data – if you need to restrict the result to a specific field
- Grouping based on similarity – our search technology can group photos of the same product as one item
- Security and privacy of your data – only meta-data and the visual representation of the images are stored, therefore your images are not stored anywhere
- The service is affordable and cost-effective both for startups and enterprises, offering free plan for tests as well as discounts with your growth over time
- We can deploy it on your hardware, independently of our infrastructure, and also offline – custom similarity model and deployment appropriate to your needs
- Our search engine and machine learning models improve constantly – maintaining much higher quality than any other open-source project & we are able to build custom search engines with trained models
Applications Using Visual Similarity
According to this research by Deloitte, merchandising with artificial intelligence is more and more relevant, and recommendation engines play a vital part in it. Here are a few use cases for visual similarity engines:
- E-shops that use product similarity to help customers to browse and find related products (e.g. in fashion & luxury items, home decor & furniture, art, wall art, prints & posters, collectible trading cards, comics, trademarks, etc.)
- Stock photo databases suggesting similar content – getting visual alternatives of photos, designs, product images, and videos
- Finding the exact products – apps like Vivino for finding wine or any kind of product are easy to develop for us
- Visual similarity duplicate finder (also image matching or deduplication), to know which images are already in your database, or which product photos you can merge together
- Reverse image search – finding a product or an image with a picture online
- Finding similar real estate based for example on interior design, furniture, garden, etc.
- Comparing two images for similarity – for example patterns or designs

Recommending products to your customers has several advantages. Firstly, it creates a better user experience and helps your customers find the right products faster. Secondly, it instantly makes the purchase rate on your web higher. This means a win on both sides – satisfied customers and higher revenue for you. Read more about customer experience and product recommendations in our blog post on fashion search.
Step by step: Building Real-Estate Image Search
Creating the Collection
So let’s take a look at how to easily build your own similarity search engine with the Ximilar platform. The first step is to log in to the Ximilar App. If you don’t have an account, then sign up – it’s free and takes just a minute. After that, on the Dashboard, click on the Visual Search tile and then the Image Similarity service. Then go to the Collections in the left menu and click on Create New Collection. It will show a pop-up with different collection types from which you need to select one.
The collection is a space where you upload your images. With this collection, you are performing queries for search. You can choose from Generic Photo Collection, Product Photo Collection, Dominant Colors Similarity, and Image Matching. Clicking on one of the cards will create a collection for your account.
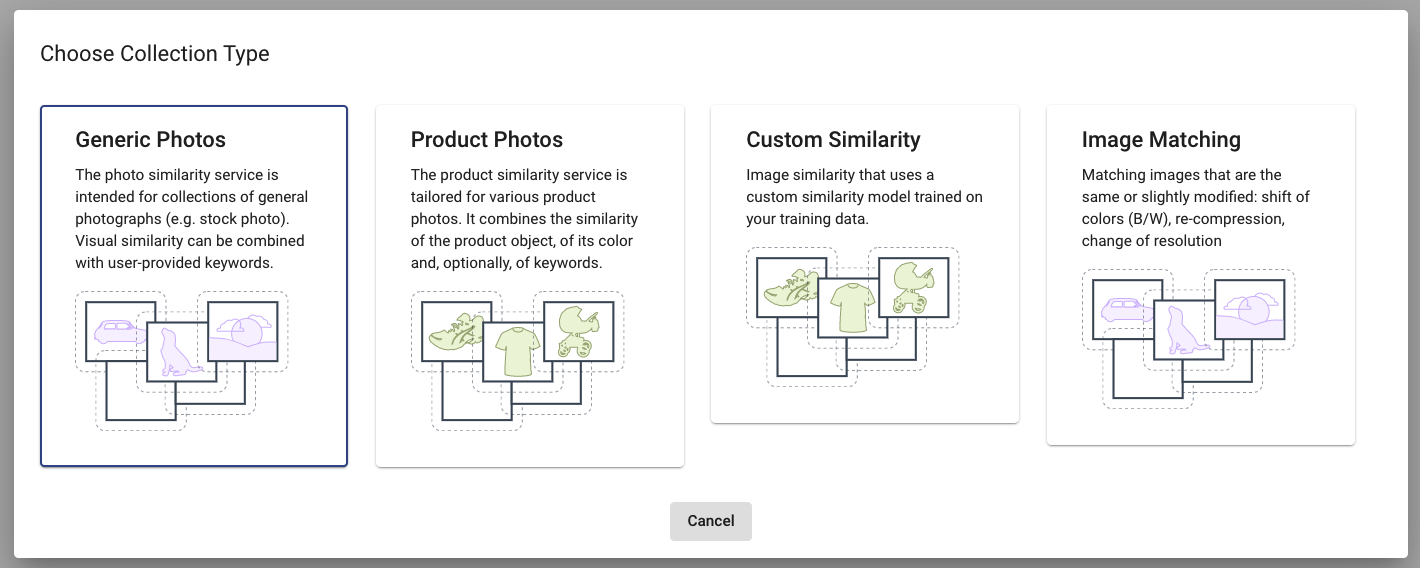
Each of these collection types is suitable for different types of images:
- Use Generic Photos if you work with stock photos
- Pick a Product Photos collection if you are an e-commerce company
- Select Image Matching to find duplicates in your images
- For the fashion sector, we recommend using a specialized service called Fashion Search
- Custom Similarity is suitable if you are working with another type of data (e.g. videos or 3D models). To do this, please schedule a call with us, and we will develop your own model tuned for your data. For instance, we built a photo search system for the Magic the Gathering Trading Cards for one of our customers.
For this example of real estate, I will use a Generic Photo Collection. The advantage of Generic Photo Collection is that it also supports searching images via text input/query. We usually develop custom similarity models for real estate, when the customers need specific and more accurate results. However, for this simple use case, the generic real estate model will be enough.
Format of Image Similarity Dataset

First, we need to prepare a text file with JSON records. Each record represents an image that we want to store/insert into our collection. The key field is "_url" with the image URL. The advantage of the _url is that you can directly see and inspect the results via app.ximilar.com.
You can also optionally send records with base64 data, this is great if your data are stored locally on your computer. Don’t worry, we are not storing the whole images (data or base64) in the collection database, just URLs with all other metadata present in the records.
The JSON records look like this:
{"_id": "1_1", "_url": "_URL_IMAGE_PATH_", "estate_id": "1", "category": "indoor", "subcategory": "kitchen", "tags": []}
{"_id": "1_2", "_url": "_URL_IMAGE_PATH_", "estate_id": "1", "category": "indoor", "subcategory": "kitchen", "tags": []}
...
If you don’t have image URLs, you can use either "_file" or "_base64" fields for the image data (locally stored "_file" data are automatically converted by the Python client to base64). The image similarity engine is indexing every record of the collection by extracting a representation from the image by a neural network model. However, we are not storing the images in our engine. So, only records that contain "_url" will be visualized in the Ximilar App.
You must store unique identifiers of each image in the "_id" field to identify your images in the collection. The value of this field must be a string. The API endpoint for searching is returning this _id values, that is how you get the results for visual search. You can also store additional fields for every JSON record, and then you can use these fields for filtering, grouping, and tuning the similarity function (see below).
Filling the Collection With Your Data
The next step requires a few lines of code. We are going to insert the prepared images into our collection using our python-client library. You can install the library using pip or directly from GitLab. The usage of the client is very straightforward and basically, you can just use the script tools/collections/insert_json_records.py:
python insert_json_records.py --type generic --auth_token __YOUR_TOKEN__ --collection_id __COLLECTION_ID__ --path /path/to/the/file.json
You will find the collection ID and the Authorization token on the “collection page” in the Ximilar App. This script will run for a few minutes, depending on the size of your image dataset.
Result: Finding Visually Similar Pictures
That was pretty easy, right? Now, if you go to the collections page, you will see something like this:
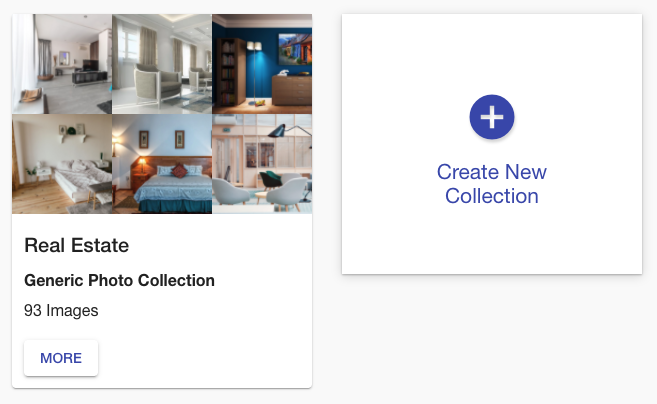
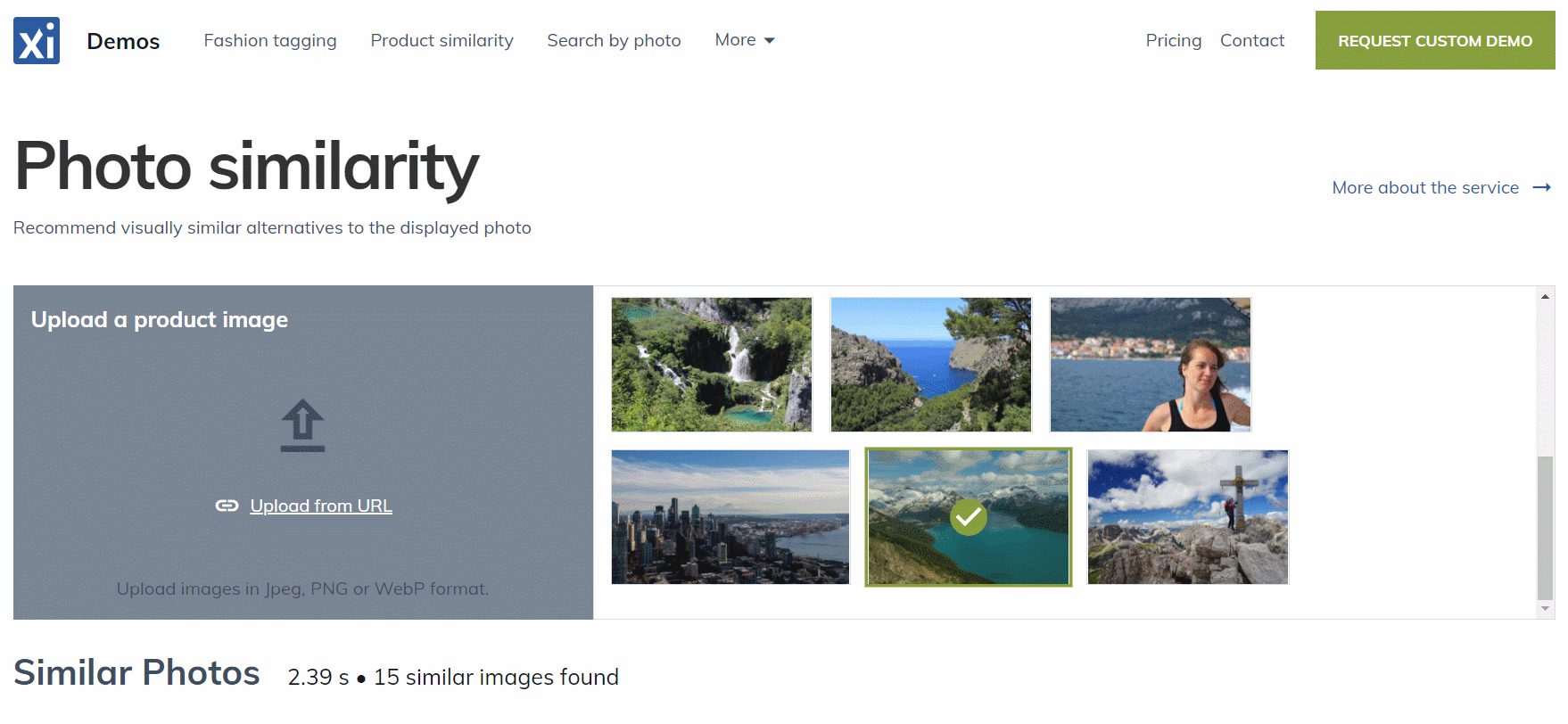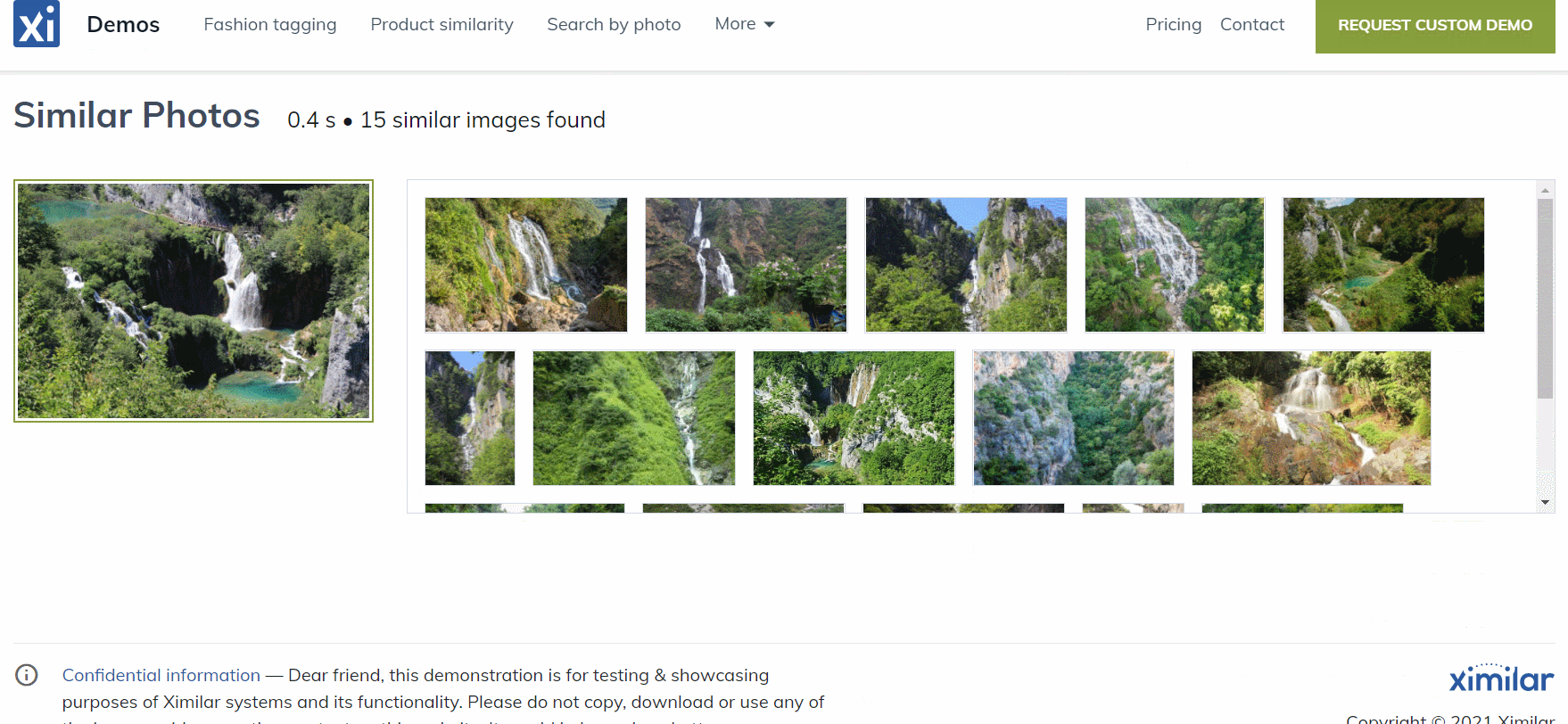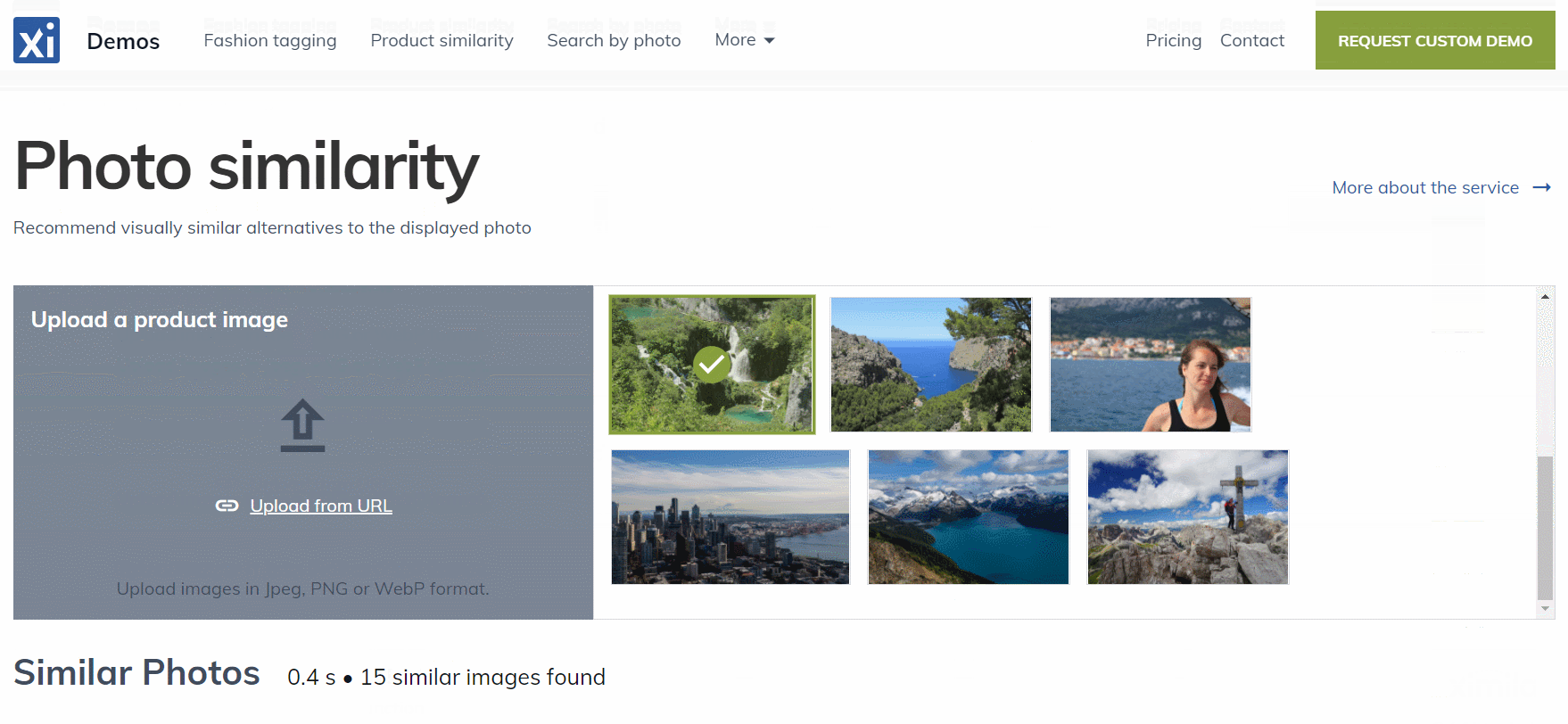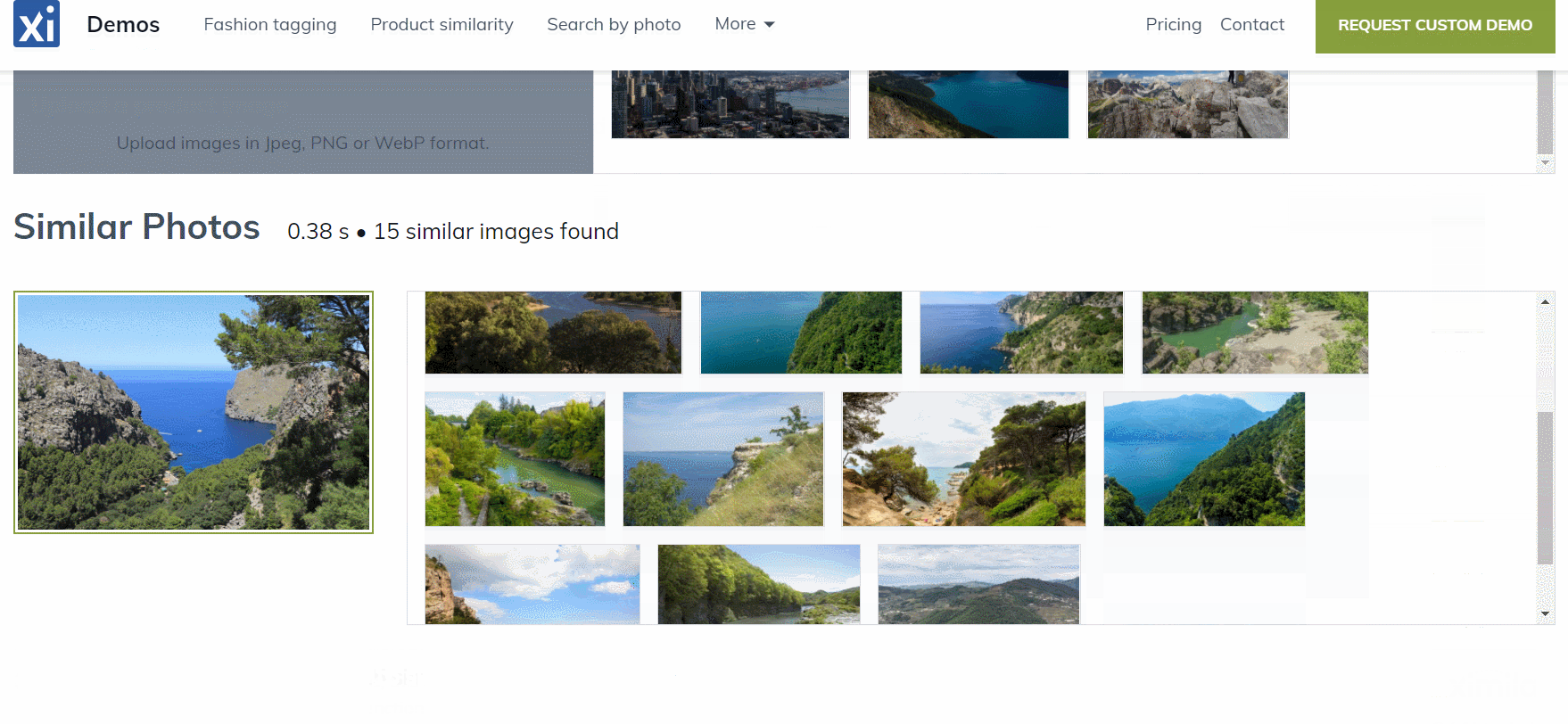
All images from the JSON file were indexed, and now you can inspect the collection in the Ximilar App. Select the Similarity Search in the left menu of the Image Similarity service and test how the similarity works. You can specify the query image either by upload, by URL, or your IDs, or by choosing one of the randomly selected images from the collection.
Even though we have indexed just several hundred images, you can see that the similarity engine works pretty well. The first image is the query image and the next images are the k-nearest to the query image:

Rest API Connection for Image Search
The next step might be to integrate the service into your application via API. You can either directly use the REST API for searching visually similar images or, if you are using Python, we recommend our Python SDK client like this:
# pip install ximilar-client
from ximilar.client import SimilarityPhotosClient
client = SimilarityPhotosClient("_API_TOKEN_", "_COLLECTION_ID_")
# search k nearest items
client.search({"_id": "1"}, k = 3)
# search by external image
client.search({"_url": "_URL_PATH_"})
Advanced Features for Photo Similarity
The search for visually similar images can be combined with filtering on metadata. This metadata can be stored in the JSON, as in our example with the "category" and "subcategory" fields. In the API, the filtering is specified using a MongoDB-like syntax – see the documentation.
For example, let’s say that we want to search for images similar to the image with ID=1_1 that are indoor photos made in a kitchen. We assume that this meta-information is stored in the “category” and “subcategory” fields of every JSON record. The query will look like this:
client.search({"_id": "1_1"}, filter={"category": "Indoor", "subcategory": "Kitchen"})
If we know that we will often filter on some fields, we can specify them in the “Fields to index” option of the collection to make the query processing more efficient.
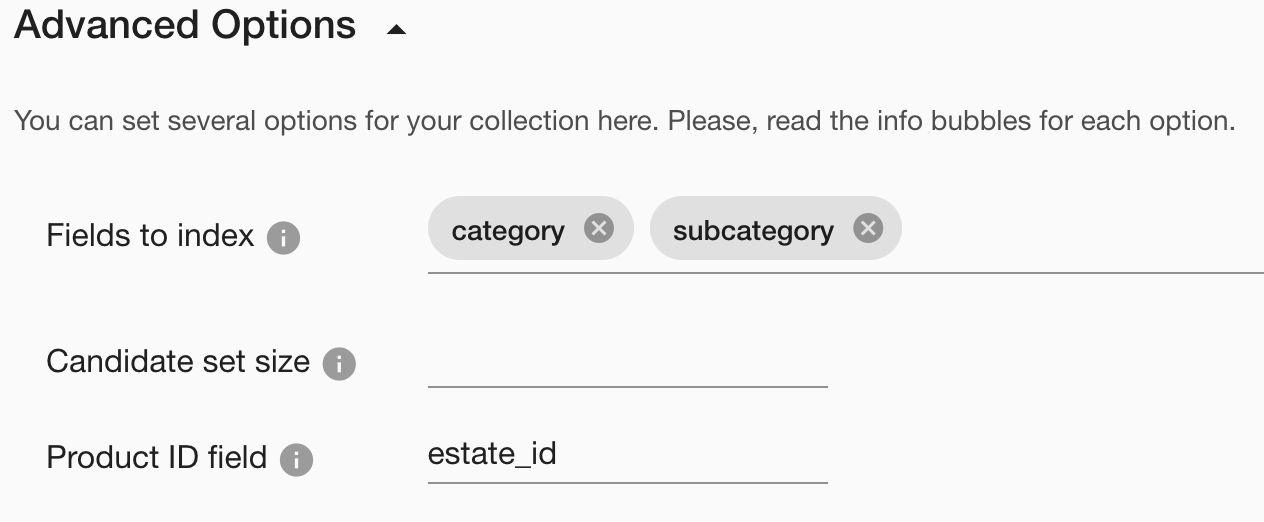
Often, your data contains several photos of one “object” – a product or, in our example, real estate. Our service can group the search results not by individual photos but by product IDs. You can set this in the advanced options of the collection by specifying the name of the real estate in the Product ID field, and the magic will happen.
Enhancing Image Similarity Engine with Tags
The image similarity is based purely on the visual content of the image. However, you can use your tags (labels, keywords) to enhance the similarity search. In the example, we assume that the data already contains categories, subcategories, and tags. In order to enhance the visual similarity search with tags, you can fill the “tags” field for every record with your tags, and also use method /v2/visualTagsKNN. After that, your search results will be based on a combination of visual similarity and keywords.
If you don’t have categories and tags, you can create your own photo tagger through our Image Recognition service, and enrich your image data automatically before indexing. The possibilities of image recognition models and their combinations are endless, resulting in highly customizable solutions. Read our guide on how to build your own Image Recognition API.

You can build several models:
- One classifier for categorizing indoor/outdoor/floor plan photos
- One classifier for getting room type (Bedroom, Kitchen, Living room, etc.)
- One tagger for outdoor tags like (Pool, Garden, Garage, House view, etc.)
To Sum Up
The real estate photo similarity search is only one use case of visual similarity from many (fashion, e-commerce, art, stock photos, healthcare…). We hope that you will enjoy working with this service, and we are looking forward to seeing your projects based on it. Thanks to our developers Libor and Ludovit, you can use this service through the frontend app.
Visual Similarity service by Ximilar is unique in terms of search quality, speed performance, and all the possibilities of the API. Our engineers are constantly upgrading the quality of the search, so you don’t have to. We are able to build custom solutions suitable for your data. With multiple collections, you can even A/B test the performance on your websites. This can run in our cloud as SaaS or in your warehouse! If you have more questions about pricing, and technical details, or you would like to run the similarity search engine on your own machines, then contact us.

Tags & Themes
Related Articles
Naruto Mythos Card Recognition – Now in Our TCG AI
Ximilar’s card recognition AI now identifies English Naruto Mythos TCG cards – name, set, rarity, and other details returned directly from the API.

Duel Masters Card Recognition – Now in Our TCG AI
Our card recognition AI now scans and identifies Japanese Duel Masters trading cards in a single REST API response.

The Ultimate Guide to LLM Fine-Tuning Platforms and Tools
The best LLM fine-tuning platforms and tools, from training and deployment to inspecting custom language models.