How to Build a Good Visual Search Engine?
Let’s take a closer look at the technology behind visual search and the key components of visual search engines.


Visual search is one of the most-demanded computer vision solutions. Our team in Ximilar have been actively developing the best general multimedia visual search engine for retailers, startups, as well as bigger companies, who need to process a lot of images, video content, or 3D models.
However, a universal visual search solution is not the only thing that customers around the world will require in the future. Especially smaller companies and startups now more often look for custom or customizable visual search solutions for their sites & apps, built in a short time and for a reasonable price. What does creating a visual search engine actually look like? And can a visual search engine be built by anyone?
This article should provide a bit deeper insight into the technology behind visual search engines. I will describe the basic components of a visual search engine, analyze approaches to machine learning models and their training datasets, and share some ideas, training tips, and techniques that we use when creating visual search solutions. Those who do not wish to build a visual search from scratch can skip right to Building a Visual Search Engine on a Machine Learning Platform.
What Exactly Does a Visual Search Engine Mean?
The technology of visual search in general analyses the overall visual appearance of the image or a selected object in an image (typically a product), observing numerous features such as colours and their transitions, edges, patterns, or details. It is powered by AI trained specifically to understand the concept of similarity the way you perceive it.
In a narrow sense, the visual search usually refers to a process, in which a user uploads a photo, which is used as an image search query by a visual search engine. This engine in turn provides the user with either identical or similar items. You can find this technology under terms such as reverse image search, search by image, or simply photo & image search.
However, reverse image search is not the only use of visual search. The technology has numerous applications. It can search for near-duplicates, match duplicates, or recommend more or less similar images. All of these visual search tools can be used together in an all-in-one visual search engine, which helps internet users find, compare, match, and discover visual content.
And if you combine these visual search tools with other computer vision solutions, such as object detection, image recognition, or tagging services, you get a quite complex automated image-processing system. It will be able to identify images and objects in them and apply both keywords & image search queries to provide as relevant search results as possible.
Different computer vision systems can be combined on Ximilar platform via Flows. If you would like to know more, here’s an article about how Flows work.
Typical Visual Search Engines:
Google Lens & Pinterest Lens
Big visual search industry players such as Shutterstock, eBay, Pinterest (Pinterest Lens) or Google Images (Google Lens & Google Images) already implemented visual search engines, as well as other advanced, yet hidden algorithms to satisfy the increasing needs of online shoppers and searchers. It is predicted, that a majority of big companies will implement some form of soft AI in their everyday processes in the next few years.
The Algorithm for Training
Visual Similarity
The Components of a Visual Search Tool
Multimedia search engines are very powerful systems consisting of multiple parts. The first key component is storage (database). It wouldn’t be exactly economical to store the full sample (e.g., .jpg image or .mp4 video) in a database. That is why we do not store any visual data for visual search. Instead, we store just a representation of the image, called a visual hash.
The visual hash (also visual descriptor or embedding) is basically a vector, representing the data extracted from your image by the visual search. Each visual hash should be a unique combination of numbers to represent a single sample (image). These vectors also have some mathematical properties, meaning you can compare them, e.g., with cosine, hamming, or Euclidean distance.
So the basic principle of visual search is: the more similar the images are, the more similar will their vector representations be. Visual search engines such as Google Lens are able to compare incredible volumes of images (i.e., their visual hashes) to find the best match in a hundred milliseconds via smart indexing.
How to Create a Visual Hash?
The visual hashes can be extracted from images by standard algorithms such as PHASH. However, the era of big data gives us a much stronger model for vector representation – a neural network. A simple overview of the image search system built with a neural network can look like this:
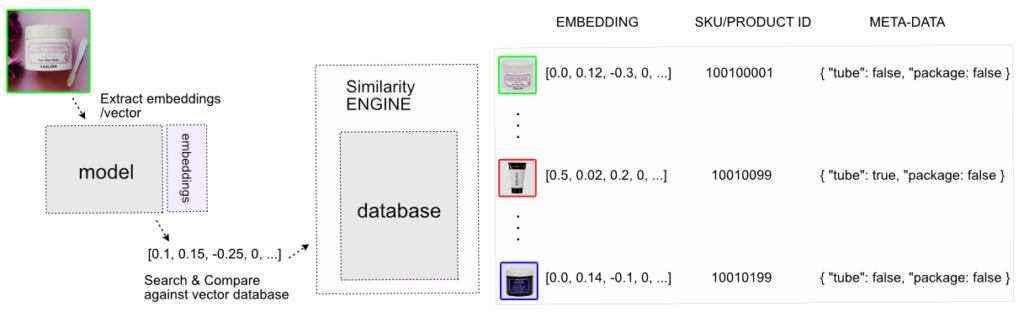
This neural network was trained on images from a website selling cosmetics. Here, it extracted the embeddings (vectors), and they were stored in a database. Then, when a customer uploads an image to the visual search engine on the website, the neural network will extract the embedding vector from this image as well, and use it to find the most similar samples.
Of course, you could also store other metadata in the database, and do advanced filtering or add keyword search to the visual search.
Types of Neural Networks
There are several basic architectures of neural networks that are widely used for vector representations. You can encode almost anything with a neural network. The most common for images is a convolutional neural network (CNN).
There are also special architectures to encode words and text. Lately, so-called transformer neural networks are starting to be more popular for computer vision as well as for natural language processing (NLP). Transformers use a lot of new techniques developed in the last few years, such as an attention mechanism. The attention mechanism, as the name suggests, is able to focus only on the “interesting” parts of the image & ignore the unnecessary details.
Training the Similarity Model
There are multiple methods to train models (neural networks) for image search. First, we should know that training of machine learning models is based on your data and loss function (also called objective or optimization function).
Optimization Functions
The loss function usually computes the error between the output of the model and the ground truth (labels) of the data. This feature is used for adjusting the weights of a model. The model can be interpreted as a function and its weights as parameters of this function. Therefore, if the value of the loss function is big, you should adjust the weights of the model.
How it Works
The model is trained iteratively, taking subsamples of the dataset (batches of images) and going over the entire dataset multiple times. We call one such pass of the dataset an epoch. During one batch analysis, the model needs to compute the loss function value and adjust weights according to it. The algorithm for adjusting the weights of the model is called backpropagation. Training is usually finished when the loss function is not improving (minimizing) anymore.
We can divide the methods (based on loss function) depending on the data we have. Imagine that we have a dataset of images, and we know the class (category) of each image. Our optimization function (loss function) can use these classes to compute the error and modify the model.
The advantage of this approach is its simple implementation. It’s practically only a few lines in any modern framework like TensorFlow or PyTorch. However, it has also a big disadvantage: the class-level optimization functions don’t scale well with the number of classes. We could potentially have thousands of classes (e.g., there are thousands of fashion products and each product represents a class). The computation of such a function with thousands of classes/arguments can be slow. There could also be a problem with fitting everything on the GPU card.
Loss Function: A Few Tips
If you work with a lot of labels, I would recommend using a pair-based loss function instead of a class-based one. The pair-based function usually takes two or more samples from the same class (i.e., the same group or category). A model based on a pair-based loss function doesn’t need to output prediction for so many unique classes. Instead, it can process just a subsample of classes (groups) in each step. It doesn’t know exactly whether the image belongs to class 1 or 9999. But it knows that the two images are from the same class.
Images can be labelled manually or by a custom image recognition model. Read more about image recognition systems.
The Distance Between Vectors
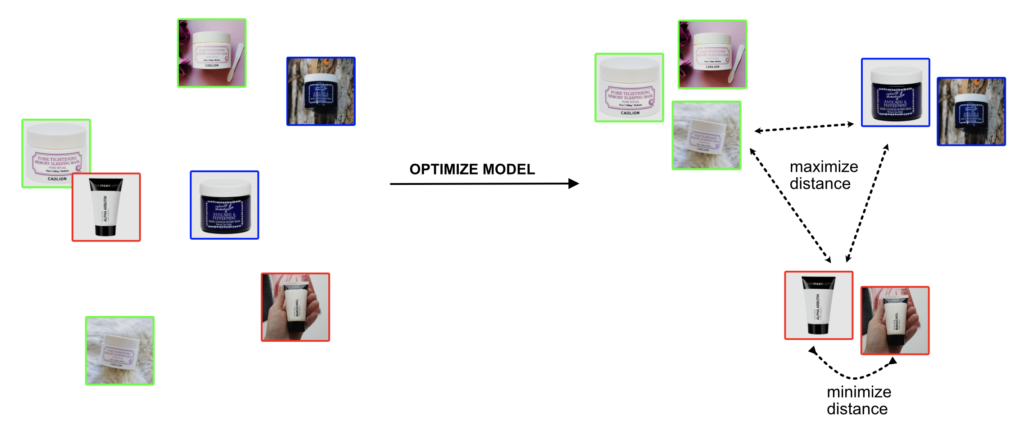
The picture below shows the data in the so-called vector space before and after model optimization (training). In the vector space, each image (sample) is represented by its embedding (vector). Our vectors have two dimensions, x and y, so we can visualize them. The objective of model optimization is to learn the vector representation of images. The loss function is forcing the model to predict similar vectors for samples within the same class (group).
By similar vectors, I mean that the Euclidean distance between the two vectors is small. The larger the distance, the more different these images are. After the optimization, the model assigns a new vector to each sample. Ideally, the model should maximize the distance between images with different classes and minimize the distance between images of the same class.
Sometimes we don’t know anything about our data in advance, meaning we do not have any metadata. In such cases, we need to use unsupervised or self-supervised learning, about which I will talk later in this article. Big tech companies do a lot of work with unsupervised learning. Special models are being developed for searching in databases. In research papers, this field is often called deep metric learning.
Supervised & Unsupervised Machine Learning Methods
1) Supervised Learning
As I mentioned, if we know the classes of images, the easiest way to train a neural network for vectors is to optimize it for the classification problem. This is a classic image recognition problem. The loss function is usually cross-entropy loss. In this way, the model is learning to predict predefined classes from input images. For example, to say whether the image contains a dog, a cat or a bird. We can get the vectors by removing the last classification layer of the model and getting the vectors from some intermediate layer of the network.
When it comes to the pair-based loss function, one of the oldest techniques for metric learning is the Siamese network (contrastive learning). The name contains “Siamese” because there are two identical models of the same weights. In the Siamese network, we need to have pairs of images, which we label based on whether they are or aren’t equal (i.e., from the same class or not). Pairs in the batch that are equal are labelled with 1 and unequal pairs with 0.
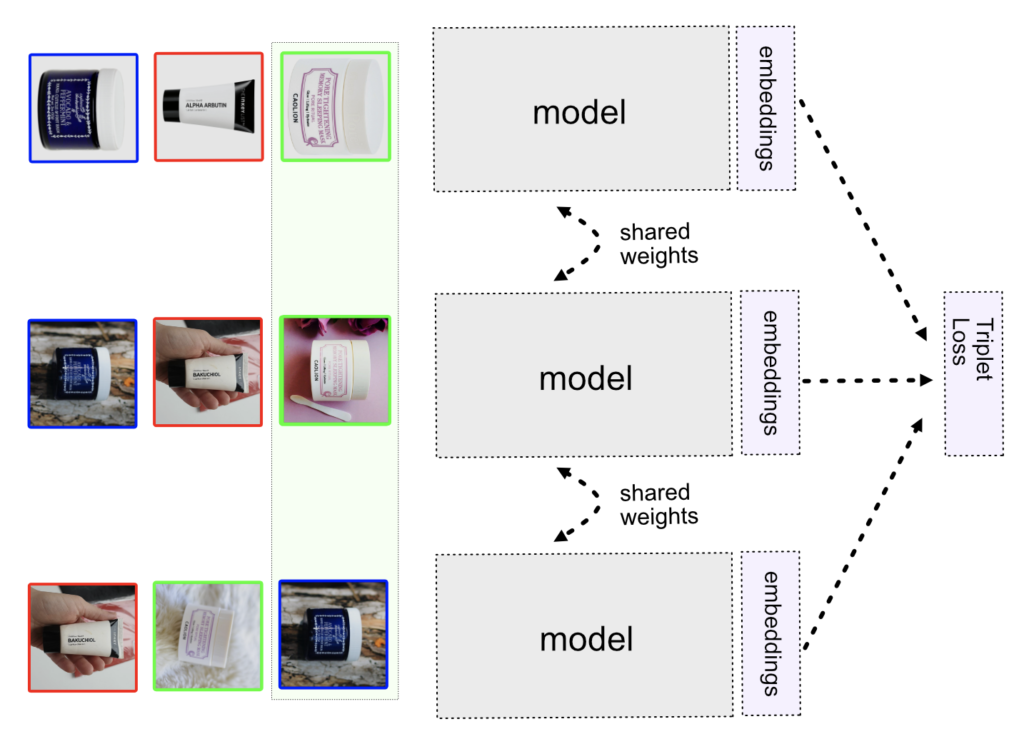
In the following image, we can see different batch construction methods that depend on our model: Siamese (contrastive) network, Triplet, or N-pair, which I will explain below.

Triplet Neural Network and Online/Offline Mining
In the Triplet method, we construct triplets of items, two of which (anchor and positive) belong to the same category and the third one (negative) to a different category. This can be harder than you might think because picking the “right” samples in the batch is critical. If you pick items that are too easy or too difficult, the network will converge (adjust weights) very slowly or not at all. The triplet loss function contains an important constant called margin. Margin defines what should be the minimum distance between positive and negative samples.
Picking the right samples in deep metric learning is called mining. We can find optimal triplets via either offline or online mining. The difference is, that during offline mining, you are finding the triplets at the beginning of each epoch.
Online & Offline Mining
The disadvantage of offline mining is that computing embeddings for each sample is not very computationally efficient. During the epoch, the model can change rapidly, so embeddings are becoming obsolete. That’s why online mining of triplets is more popular. In online mining, each batch of triplets is created before fitting the model. For more information about mining and batch strategies for triplet training, I would recommend this post.
We can visualize the Triplet model training in the following way. The model is copied three times, but it has the same shared weights. Each model takes one image from the triplet (anchor, positive, negative) and outputs the embedding vector. Then, the triplet loss is computed and weights are adjusted with backpropagation. After the training is done, the model weights are frozen and the output of the embeddings is used in the similarity engine. Because the three models have shared weights (the same), we take only one model that is used for predicting embedding vectors on images.
N-pair Models
The more modern approach is the N-pair model. The advantage of this model is that you don’t mine negative samples, as it is with a triplet network. The batch consists of just positive samples. The negative samples are mitigated through the matrix construction, where all non-diagonal items are negative samples.
You still need to do online mining. For example, you can select a batch with a maximum value of the loss function, or pick pairs that are distant in metric space.
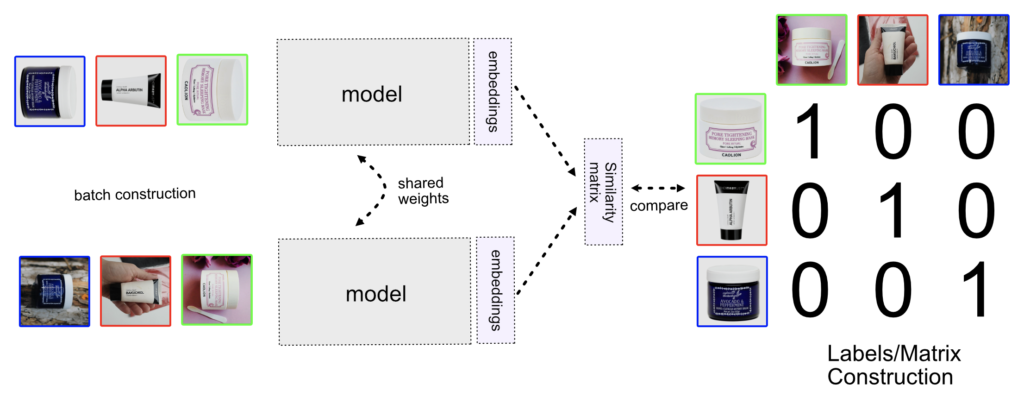
In our experience, the N-pair model is much easier to fit, and the results are also better than with the triplet or Siamese model. You still need to do a lot of experiments and know how to tune other hyperparameters such as learning rate, batch size, or model architecture. However, you don’t need to work with the margin value in the loss function, as it is in triplet or Siamese. The small drawback is that during batch creation, we need to have always only two items per class/product.
Proxy-Based Methods
In the proxy-based methods (Proxy-Anchor, Proxy-NCA, Soft Triple) the model is trying to learn class representatives (proxies) from samples. Imagine that instead of having 10,000 classes of fashion products, we will have just 20 class representatives. The first representative will be used for shoes, the second for dresses, the third for shirts, the fourth for pants and so on.
A big advantage is that we don’t need to work with so many classes and the problems coming with it. The idea is to learn class representatives and instead of slow mining “the right samples” we can use the learned representatives in computing the loss function. This leads to much faster training & convergence of the model. This approach, as always, has some cons and questions like how many representatives should we use, and so on.
MultiSimilarity Loss
Finally, it is worth mentioning MultiSimilarity Loss, introduced in this paper. MultiSimilarity Loss is suitable in cases when you have more than two items per class (images per product). The authors of the paper are using 5 samples per class in a batch. MultiSimilarity can bring closer items within the same class and push the negative samples far away by effectively weighting informative pairs. It works with three types of similarities:
- Self-Similarity (the distance between the negative sample and anchor)
- Positive-Similarity (the relationship between positive pairs)
- Negative-Similarity (the relationship between negative pairs)
Finally, it is also worth noting, that in fact, you don’t need to use only one loss function, but you can combine multiple loss functions. For example, you can use the Triplet Loss function with CrossEntropy and MultiSimilarity or N-pair together with Angular Loss. This should often lead to better results than the standalone loss function.
2) Unsupervised Learning
AutoEncoder
Unsupervised learning is helpful when we have a completely unlabelled dataset, meaning we don’t know the classes of our images. These methods are very interesting because the annotation of data can be very expensive and time-consuming. The most simplistic unsupervised learning can simply use some form of AutoEncoder.
AutoEncoder is a neural network consisting of two parts: an encoder, which encodes the image to the smaller representation (embedding vector), and a decoder, which is trying to reconstruct the original image from the embedding vector.
After the whole model is trained, and the decoder is able to reconstruct the images from smaller vectors, the decoder part is discarded and only the encoder part is used in similarity search engines.
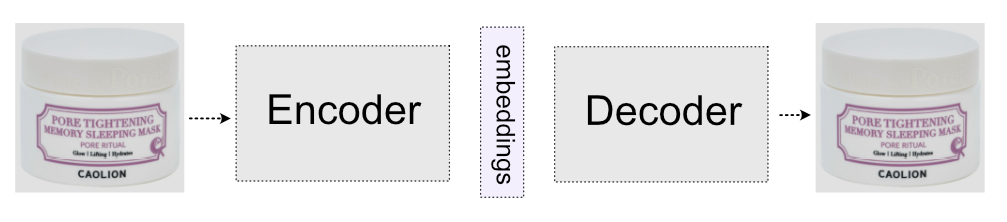
There are many other solutions for unsupervised learning. For example, we can train AutoEncoder architecture to colourize images. In this technique, the input image has no colour and the decoding part of the network tries to output a colourful image.
Image Inpainting
Another technique is Image Inpainting, where we remove part of the image and the model will learn to inpaint them back. Interesting way to propose a model that is solving jigsaw puzzles or correct ordering of frames of a video.
Then there are more advanced unsupervised models like SimCLR, MoCo, PIRL, SimSiam or GAN architectures. All these models try to internally represent images so their outputs (vectors) can be used in visual search systems. The explanation of these models is beyond this article.
Tips for Training Deep Metric Models
Here are some useful tips for training deep metric learning models:
- Batch size plays an important role in deep metric learning. Some methods such as N-pair should have bigger batch sizes. Bigger batch sizes generally lead to better results, however, they also require more memory on the GPU card.
- If your dataset has a bigger variation and a lot of classes, use a bigger batch size for Multi-similarity loss.
- The most important part of metric learning is your data. It’s a pity that most research, as well as articles, focus only on models and methods. If you have a large collection with a lot of products, it is important to have a lot of samples per product. If you have fewer classes, try to use some unsupervised method or cross-entropy loss and do heavy augmentations. In the next section, we will look at data in more depth.
- Try to start with a pre-trained model and tune the learning rate.
- When using Siamese or Triplet training, try to play with the margin term, all the modern frameworks will allow you to change it (make it harder) during the training.
- Don’t forget to normalize the output of the embedding if the loss function requires it. Because we are comparing vectors, they should be normalized in a way that the norm of the vectors is always 1. This way, we are able to compute Euclidean or cosine distances.
- Use advanced methods such as MultiSimilarity with big batch size. If you use Siamese, Triplet, or N-pair, mining of negatives or positives is essential. Start with easier samples at the beginning and increase the challenging samples every epoch.
Neural Text Search on Images with CLIP
Up to right now, we were talking purely about images and searching images with image queries. However, a common use case is to search the collection of images with text input, like we are doing with Google or Bing search. This is also called Text-to-Image problem, because we need to transform text representation to the same representation as images (same vector space). Luckily, researchers from OpenAI develop a simple yet powerful architecture called CLIP (Contrastive Language Image Pre-training). The concept is simple, instead of training on pair of images (SIAMESE, NPAIR) we are training two models (one for image and one for text) on pairs of images and texts.
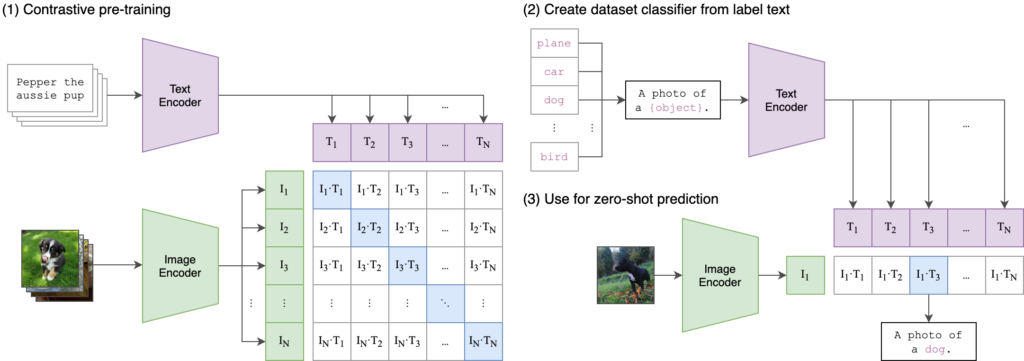
You can train a CLIP model on a dataset and then use it on your images (or videos) collection. You are able to find similar images/products or try to search your database with a text query. If you would like to use a CLIP-like model on your data, we can help you with the development and integration of the search system. Just contact us at [email protected], and we can create a search system for your data.
The Training Data
for Visual Search Engines
99 % of the deep learning models have a very expensive requirement: data. Data should not contain any errors such as wrong labels, and we should have a lot of them. However, obtaining enough samples can be a problematic and time-consuming process. That is why techniques such as transfer learning or image augmentation are widely used to enrich the datasets.
How Does Image Augmentation Help With Training Datasets?
Image augmentation is a technique allowing you to multiply training images and therefore expand your dataset. When preparing your dataset, proper image augmentation is crucial. Each specific category of data requires unique augmentation settings for the visual search engine to work properly. Let’s say you want to build a fashion visual search engine based strictly on patterns and not the colours of items. Then you should probably employ heavy colour distortion and channel-swapping augmentation (randomly swapping red, green, or blue channels of an image).
On the other hand, when building an image search engine for a shop with coins, you can rotate the images and flip them to left-right and upside-down. But what to do if the classic augmentations are not enough? We have a few more options.
Removing or Replacing Background
Most of the models that are used for image search require pairs of different images of the same object. Typically, when training product image search, we use an official product photo from a retail site and another picture from a smartphone, such as a real-life photo or a screenshot. This way, we get a pair-based model that understands the similarity of a product in pictures with different backgrounds, lights, or colours.

All such photos of the same product belong to an entity which we call a Similarity Group. This way, we can build an interactive tool for your website or app, which enables users to upload a real-life picture (sample) and find the product they are interested in.
Background Removal Solution
Sometimes, obtaining multiple images of the same group can be impossible. We found a way to tackle this issue by developing a background removal model that can distinguish the dominant foreground object from its background and detect its pixel-accurate position.
Once we know the exact location of the object, we can generate new photos of products with different backgrounds, making the training of the model more effective with just a few images.
The background removal can also be used to narrow the area of augmentation only to the dominant item, ignoring the background of the image. There are a lot of ways to get the original product in different styles, including changing saturation, exposure, highlights and shadows, or changing the colours entirely.

Building such an augmentation pipeline with background/foreground augmentation can take hundreds of hours and a lot of GPU resources. That is why we deployed our Background Removal solution as a ready-to-use image tool.
You can use the Background Removal as a stand-alone service for your image collections, or as a tool for training data augmentation. It is available in public demo, App, and via API.
GAN-Based Methods for Generating New Training Data
One of the modern approaches is to use a Generative Adversarial Network (GAN). GANs are incredibly powerful in generating whole new images from some specific domain. You can simply create a model for generating new kinds of insects or making birds with different textures.
![How visual search engines work: Creating new insect images automatically to train an image recognition system? How cool is that? There are endless possibilities with GAN models for basicaly any image type. [Source]](https://www.ximilar.com/wp-content/uploads/2023/01/gan-insect2.gif)
The greatest advantage of GAN is you will easily get a lot of new variants, which will make your model very robust. GANs are starting to be widely used in more tasks such as simulations, and I think the gathering of data will cost much less in the near future because of them. In Ximilar, we used GAN to create a GAN Image Upscaler, which adds new relevant pixels to images to increase their resolution and quality.
When creating a visual search system on our platform, our team picks the most suitable neural network architecture, loss functions, and image augmentation settings through the analysis of your visual data and goals. All of these are critical for the optimization of a model and the final accuracy of the system. Some architectures are more suitable for specific problems like OCR systems, fashion recommenders or quality control. The same goes with image augmentation, choosing the wrong settings can destroy the optimization. We have experience with selecting the best tools to solve specific problems.
Annotation System for Building Image Search Datasets
As we can see, a good dataset definitely is one of the key elements for training deep learning models. Obtaining such a collection can be quite expensive and time-consuming. With some of our customers, we build a system that continually gathers the images needed in the training datasets (for instance, through a smartphone app). This feature continually & automatically improves the precision of the deployed search engines.
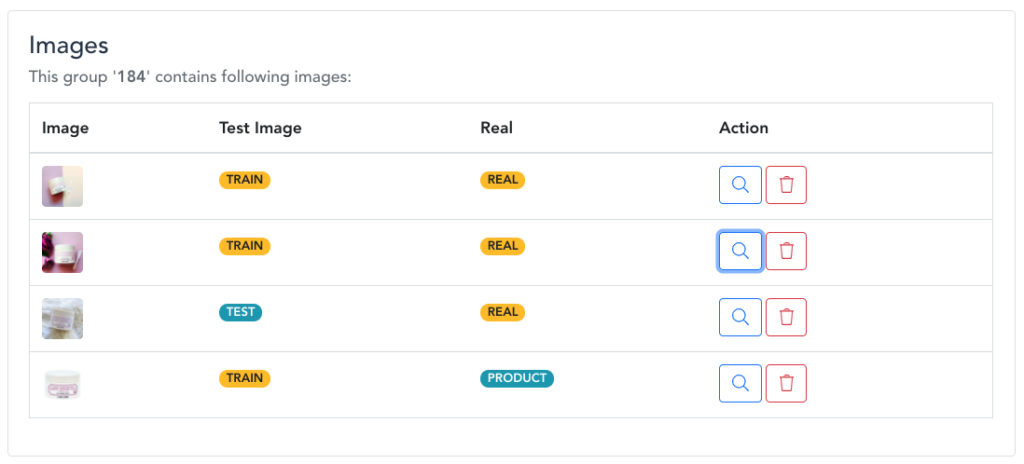
How does it work? When the new images are uploaded to Ximilar Platform (through Custom Similarity service) either via App or API, our annotators can check them and use them to enhance the training dataset in Annotate, our interface dedicated to image annotation & management of datasets for computer vision systems.
Annotate effectively works with the similarity groups by grouping all images of the same item. The annotator can add the image to a group with the relevant Stock Keeping Unit (SKU), label it as either a product picture or a real-life photo, add some tags, or mark objects in the picture. They can also mark images that should be used for the evaluation and not used in the training process. In this way, you can have two separate datasets, one for training and one for evaluation.
We are quite proud of all the capabilities of Annotate, such as quality control, team cooperation, or API connection. There are not many web-based data annotation apps where you can effectively build datasets for visual search, object detection, as well as image recognition, and which are connected to a whole visual AI platform based on computer vision.
How to Improve Visual Search Engine Results?
We already assessed that the optimization algorithm and the training dataset are key elements in training your similarity model. And that having multiple images per product then significantly increases the quality of the trained similarity model. The model (CNN or other modern architecture) for similarity is used for embedding (vector) extraction, which determines the quality of image search.
Over the years that we’ve been training visual search engines for various customers around the world, we were also able to identify several potential weak spots. Their fixing really helped with the performance of searches as well as the relevance of the search results. Let’s take a look at what can improve your visual search engine:
Include Tags
Adding relevant keywords for every image can improve the search results dramatically. We recommend using some basic words that are not synonymous with each other. The wrong keywords for one item are for instance “sky, skyline, cloud, cloudy, building, skyscraper, tall building, a city”, while the good alternative keywords would be “sky, cloud, skyscraper, city”.
Our engine can internally use these tags and improve the search results. You can let an image recognition system label the images instead of adding the keywords manually.
Include Filtering Categories
You can store the main categories of images in their metadata. For instance, in real estate, you can distinguish photos that were taken inside or outside. Based on this, the searchers can filter the search results and improve the quality of the searches. This can also be easily done by an image recognition task.
Include Dominant Colours
Colour analysis is very important, especially when working for a fashion or home decor shop. We built a tool conveniently called Dominant Colors, with several extraction options. The system can extract the main colours of a product while ignoring its background. Searchers can use the colours for advanced filtering.
Use Object Detection & Segmentation
Object detection can help you focus the view of both the search engine and its user on the product, by merely cutting the detected object from the image. You can also apply background removal to search & showcase the products the way you want. For training object detection and other custom image recognition models, you can use our App & Annotate.
Use Optical Character Recognition (OCR)
In some domains, you can have products with text. For instance, wine bottles or skincare products with the name of the item and other text labels that can be read by artificial intelligence, stored as metadata and used for keyword search on your site.

Improve Image Resolution
If the uploaded images from the mobile phones have low resolution, you can use the image upscaler to increase the resolution of the image, screenshot, or video. This way, you will get as much as possible even from user-generated content with potentially lower quality.
Combine Multiple Approaches
Fusion – Combining multiple features like model embeddings, tags, dominant colours, and text increases your chances to build a solid visual search engine. Our system is able to use these different modalities and return the best items accordingly. For example, extracting dominant colours is really helpful in Fashion Search, our service combining object detection, fashion tagging & visual search.
Search Engine and Vector Databases
Once you trained your model (neural network), you can extract and store the embeddings for your multimedia items somewhere. There are a lot of image search engine implementations that are able to work with vectors (embedding representation) that you can use. For example, Annoy from Spotify or FAISS from Facebook developers.
These solutions are open-source (i.e. you don’t have to deal with usage rights) and you can use them for simple solutions. However, they also have a few disadvantages:
- After the initial build of the search engine database, you cannot perform any update, insert or delete operations. Once you store the data, you can only perform search queries.
- You are unable to use a combination of multiple features, such as tags, colours, or metadata.
- There’s no support for advanced filtering for more precise results.
- You need to have an IT background and coding skills to implement and use them. And in the end, the system must be deployed on some server, which brings additional challenges.
- It is difficult to extend them for advanced use cases, you will need to learn a complex codebase of the project and adjust it accordingly.
Building a Visual Search Engine on a Machine Learning Platform
The creation of a great visual search engine is not an easy task. The mentioned challenges and disadvantages of building complex visual search engines with high performance are the reasons why a lot of companies hesitate to dedicate their time and funds to building them from scratch. That is where AI platforms like Ximilar come into play.
Custom Similarity Service
Ximilar provides a computer vision platform, where a fast similarity engine is available as a service. Anyone can connect via API and fill their custom collection with data and query at the same time. This streamlines the tedious workflow a lot, enabling people to have custom visual search engines fast and, more importantly, without coding. Our image search engines can handle other data types like videos, music, or 3D models. If you want more privacy for your data, the system can also be deployed on your hardware infrastructure.
In all industries, it is important to know what we need from our model and optimize it towards the defined goal. We developed our visual search services with this in mind. You can simply define your data and problem and what should be the primary goal for this similarity. This is done via similarity groups, where you put the items that should be matched together.
Examples of Visual Search Solutions for Business
One of the typical industries that use visual search extensively is fashion. Here, you can look at similarities in multiple ways. For instance, one can simply want to find footwear with a colour, pattern, texture, or shape similar to the product in a screenshot. We built several visual search engines for fashion e-shops and especially price comparators, which combined search by photo and recommendations of alternative similar products.
Based on a long experience with visual search solutions, we deployed several ready-to-use services for visual search: Visual Product Search, a complex visual search service for e-commerce including technologies such as search by photo, similar product recommendations, or image matching, and Fashion Search created specifically for the fashion segment.
Another nice use case is also the story of how we built a Pokémon Trading Card search engine. It is no surprise that computer vision has been recently widely applied in the world of collectibles. Trading card games, sports cards or stamps and visual AI are a perfect match. Based on our customers’ demand, we also created several AI solutions specifically for collectibles.
The Workflow of Building
a Visual Search Engine
If you are looking to build a custom search engine for your users, we can develop a solution for you, using our service Custom Image Similarity. This is the typical workflow of our team when working on a customized search service:
Setup, Research & Plan – Initial calls, the definition of the project, NDA, and agreement on expected delivery time.
Data – If you don’t provide any data, we will gather it for you. Gathering and curating datasets is the most important part of developing machine learning models. Having a well-balanced dataset without any bias to any class leads to great performance in production.
First prototype – Our machine learning team will start working on the model and collection. You will be able to see the first results within a month. You can test it and evaluate it by yourself via our clickable front end.
Development – Once you are satisfied with the results, we will gather more data and do more experiments with the models. This is an iterative way of improving the model.
Evaluation & Deployment – If the system performs well and meets the criteria set up in the first calls (mostly some evaluation on the test dataset and speed performance), we work on the deployment. We will show you how to connect and work with the API for visual similarity (insert, delete, search endpoints).
If you are interested in knowing more about how the cooperation with Ximilar works in general, read our How it works and contact us anytime.
We are also able to do a lot of additional steps, such as:
- Managing and gathering more training data continually after the deployment to gradually increase the performance of visual similarity (the usage rights for user-generated content are up to you; keep in mind that we don’t store any physical images).
- Building a customized model or multiple models that can be integrated into the search engine.
- Creating & maintaining your visual search collection, with automatic synchronization to always keep up to date with your current stock.
- Scaling the service to hundreds of requests per second.
Visual Search is Not Only
For the Big Companies
I presented the basic techniques and architectures for training visual similarity models, but of course, there are much more advanced models and the research of this field continues with mile steps.
Search engines are practically everywhere. It all started with AltaVista in 1995 and Google in 1998. Now it’s more common to get information directly from Siri or Alexa. Searching for things with visual information is just another step, and we are glad that we can give our clients tools to maximise their potential. Ximilar has a lot of technical experience with advanced search technology for multimedia data, and we work hard to make it accessible to everyone, including small and medium companies.
If you are considering implementing visual search into your system:
Schedule a call with us and we will discuss your goals. We will set up a process for getting the training data that are necessary to train your machine learning model for search engines.
In the following weeks, our machine learning team will train a custom model and a testable search collection for you.
After meeting all the requirements from the POC, we will deploy the system to production, and you can connect to it via Rest API.

Tags & Themes
Related Articles
Vision Language Model Evaluation & Inspection Made Easy
From loss curves to GGUF exports – mastering your vision language model evaluation workflow with built-in metrics.
Fine-Tuning a Vision Language Model With the Ximilar API
Fine-tune your vision-language model with image understanding, run it on your own hardware, and cut your per-inference token costs.

Korean and Thai Pokémon Cards Now Supported in Our AI Recognition System
Ximilar’s card recognition AI now identifies Korean and Thai Pokémon trading cards, returning native-language card data alongside the standard identification fields. Let’s see it in action!