How to Fine-Tune a Vision Language Model Without Writing Code
Ximilar’s no-code VLM platform lets you fine-tune small, private AI models and deploy them on any device – no ML expertise required.

Until recently, building and deploying your own vision language model – AI that understands both images and text – meant hiring ML engineers, managing GPU infrastructure, and writing thousands of lines of code. That barrier is now gone. Modern, efficient models can run on a laptop, process text and image data together, answer questions about your images, and be fine-tuned on your own data.
In this article, we walk you through how to fine-tune a private, domain-specific vision language model in five steps at Ximilar’s no-code platform – no Python, no Docker, no ML expertise required. From choosing your base model and structuring your data, to deploying offline on your own hardware, we cover everything you need to go from idea to production. Let’s get into it.
Small Models, Big Results: The Case for Fine-Tuned VLMs
The era of massive, expensive AI models running in faraway datacenters is giving way to something more practical: small, fine-tuned vision language models (VLMs) that run on your own hardware and understand your specific domain. Open-source releases such as Google’s Gemma, Alibaba’s Qwen3-VL, and LiquidAI’s LFM2 have made this possible – these models can run on a laptop, a smartphone, or an edge device.
Unlike older systems where language models trained on text and vision models are trained separately, today these models are trained end-to-end on combined vision and text data. No datacenter required.
“The timing could not be better. While massive foundation models have captured attention, the true breakthrough in code generation lies in smaller, specialized models paired with optimized deployment infrastructure.”
Andreesen Horowitz – Investing in Relace
This matters because most businesses do not need an omniscient artificial intelligence. They need a VLM that understands their domain and does one thing well, be it classifying their products, generating image captions, reading their documents, or analysing their images – fast, cheap, and without sending data to a third party.
We believe the future belongs to small, efficient models built around your private know-how, a view shared by researchers at both NVIDIA and Liquid AI.
Why Fine-Tune Models Instead of Using ChatGPT or Claude?
Popular large language models (LLMs) such as GPT-5 or Gemini are powerful, but they are closed, generalist systems trained to know a little about everything.
In contrast, fine-tuned vision language models trained on your own data consistently outperform generic large models on the metrics that matter, delivering a level of precision, efficiency, and control that no amount of prompt engineering – or even the strongest general LLM – can replicate.
Vision–Language Understanding
Using vision and natural language together, VLMs learn to map visual inputs to structured text outputs. Unlike text-only language models, they can interpret images as part of their reasoning process. During VLM training, the model learns how specific visual patterns correspond to domain-relevant outputs, enabling reliable, structured predictions.
VLMs can be fine-tuned with as little as 200 to 3,000 labeled examples using techniques like LoRA (Low-Rank Adaptation), making them both practical and highly specialized.
Domain-Specific Features
A fine-tuned VLM knows your domain inside out – your product taxonomy, your medical terminology, or document layouts – in a way generic systems cannot replicate.
VLMs use domain-specific data to solve problems no generic model can. From classifying skin lesions in dermatology and catching sub-millimeter solder defects on circuit boards, to reading damaged wine labels and spotting sick cattle from drone footage – fine-tuned VLMs are already solving highly specific visual problems across different industries.
ChatGPT does not know your business rules or edge cases, no matter how clever your system prompt is. Instead of relying on prompts alone, the vision language learns directly from real examples, capturing edge cases and implicit rules that are difficult to encode manually.
Cost Efficiency & Resource Optimization
After a one-time training fee (starting at approximately $10 for your smallest model), inference on your own hardware is essentially free. In contrast, API-based pricing – such as $0.01–$0.03 per call – scales with every request.
For applications handling thousands of daily inputs and outputs, this quickly becomes the difference between predictable infrastructure costs and a usage-based bill that grows with your user base.
Privacy & Security Concerns
Finally, there is privacy. When you call a cloud API, your data is transmitted to external servers. For GDPR-regulated industries, healthcare imaging, trade secrets, or other sensitive visual inputs, that introduces significant risk.
A fine-tuned VLM deployed on your own infrastructure keeps all inputs and outputs in-house, ensuring full control over data handling, compliance, and security.
Ximilar is one of the first platforms in the world to offer no-code fine-tuning for vision language models.
How Vision Language Models Work: Architecture Overview
VLMs – also called visual language models or visual language systems – combine two main components: an image encoder that processes image inputs, and a decoder (usually a large language model) that generates text outputs.
The visual processing unit – typically a vision transformer (ViT) or a convolutional neural network – converts visual information into a sequence of feature embeddings. Siglip and DeepStack ViT convert raw pixels into rich visual features that help models reason about visual content alongside text tokens.
This is what enables the model to reason across vision and language simultaneously – bridging vision and language in a single model rather than chaining separate systems. And it is also what separates VLMs from both traditional computer vision pipelines and basic natural language processing systems, which work on text alone.
A fine-tuned small VLM outperforms a generic large LLMs on every metric that matters.
The decoder then takes those visual embeddings and any text input together and uses a transformer to generate a response. Models like LLaVA – which combined masked language modeling objectives with visual pretraining – showed early on that connecting a pretrained vision encoder to a large LLM enables surprisingly strong vision and natural language understanding. These models can process both image and text data simultaneously, and models also benefit from the continued improvements in open-source transformer models.
Training VLMs without code was simply not possible on most platforms until now. Ximilar is one of the first platforms in the world to offer no-code fine-tuning specifically for vision language models.
When you fine-tune a model on Ximilar, you train the model end-to-end to predict exactly what your business needs from each image – mapping both your specific vision and text data to your desired outputs. This enables the model to predict structured results directly from visual data.
Examples of Vision Language Model Uses
Here is what our users are building using VLMs fine-tuned on our platform:
- Private document processing – Extracting structured data from invoices, contracts, and PDFs without sending them to external servers. Similar to what Rossum.ai does, but running entirely on your infrastructure.
- Real estate image analysis – Classifying property types, room layouts, and condition from listing photos, replacing hours of manual review per batch.
- Medical imaging – On-premise X-ray and scan recognition where patient data cannot leave the facility.
- Aerial and drone footage analysis – Running vision models directly on edge devices in the field, with no dependency on internet connectivity.
How to Train a Vision-Language Model Without Coding
We are launching a privacy-first system that lets you train efficient vision language models on the Ximilar platform – without writing a single line of code and without any ML expertise. You’ll get a multimodal model that understands images and text, answers visual questions, and generates outputs from your instructions.
Unlike general-purpose AI labs building massive multimodal models, we focus exclusively on small, efficient vision language models designed for specific vision tasks. We handle the full training pipeline while you focus on your product, not on infrastructure.
Five Steps, Zero Code
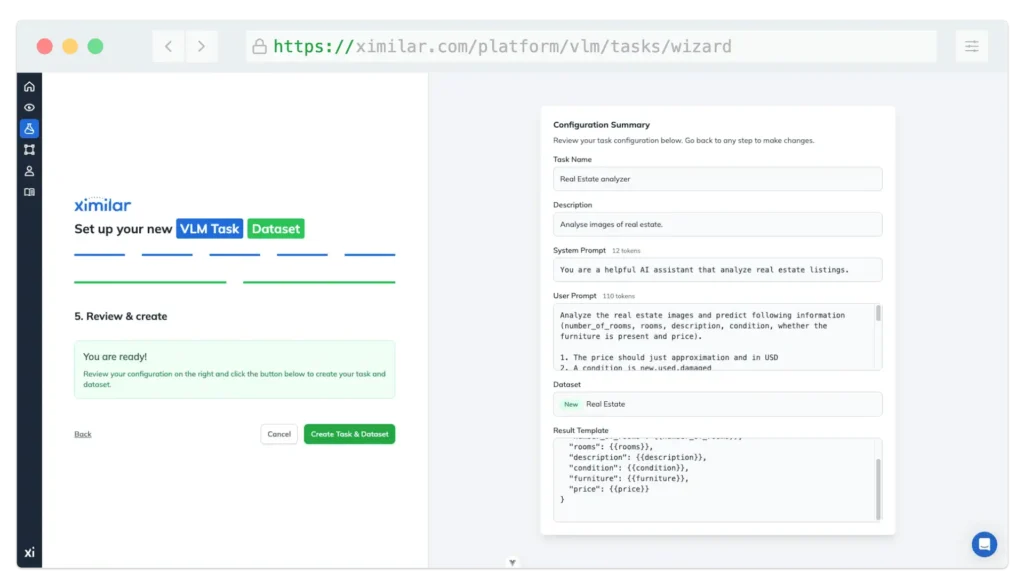
Here’s the full workflow:
- Create your account at Ximilar App and open the VLM Dashboard.
- Create a Task via the wizard – it walks you through configuring the model type, instruction templates, token limits, and augmentation settings. You will also set up a dataset that defines how your training samples are structured.
- Add your Training samples – a few hundred to start (for LoRA), ideally a few thousand for best results.
- Click Train and wait a few hours while the model trains on our GPUs.
- Review the evaluation results & download your model – Once training is complete, you can review evaluation metrics for better evaluation of model quality, run iterative tests directly in the dashboard, and either use the model via our REST API or download the fine-tuned weights to run offline.
Models built on our platform can be adapted via fine-tuning for a single use case and then deployed wherever you need them – including entirely offline. Your data, your model, your terms. If you know how to code, you can be even more effective using our API for data management, but it is not required.

Ximilar’s no-code platform for visual AI already powers hundreds of production systems – from fashion tagging to the world’s best AI trading card scanner. Models can be combined via our Flow service and deployed as REST API endpoints. The VLM service extends this platform with language model capabilities.
Managing Tasks, Datasets, and Samples
Behind the simple five-step workflow is a structured system that gives you full control over how the model learns. Everything in Ximilar’s VLM platform revolves around four core concepts: Tasks, Datasets, Prompts (or Templates), and Samples.
Tasks
A Task is the top-level definition of your training job. It specifies which base model to fine-tune, connects datasets and holds configuration settings such as token limits and augmentation. Each Task carries:
- Default system prompt – a high-level instruction for training the model in the right direction, such as “You are a product-description assistant for fashion e-commerce”.
- User prompt that defines how individual inputs are framed during training.
Datasets
A Dataset defines the structure of your training data for VLMs. It has its own system prompt and user prompt (the input the model sees), plus a result template that describes the desired output (including format).
The result template uses variables – named placeholders such as {{brand}}, {{category}}, or {{condition}} – that represent the specific pieces of information you want the model to extract or generate.
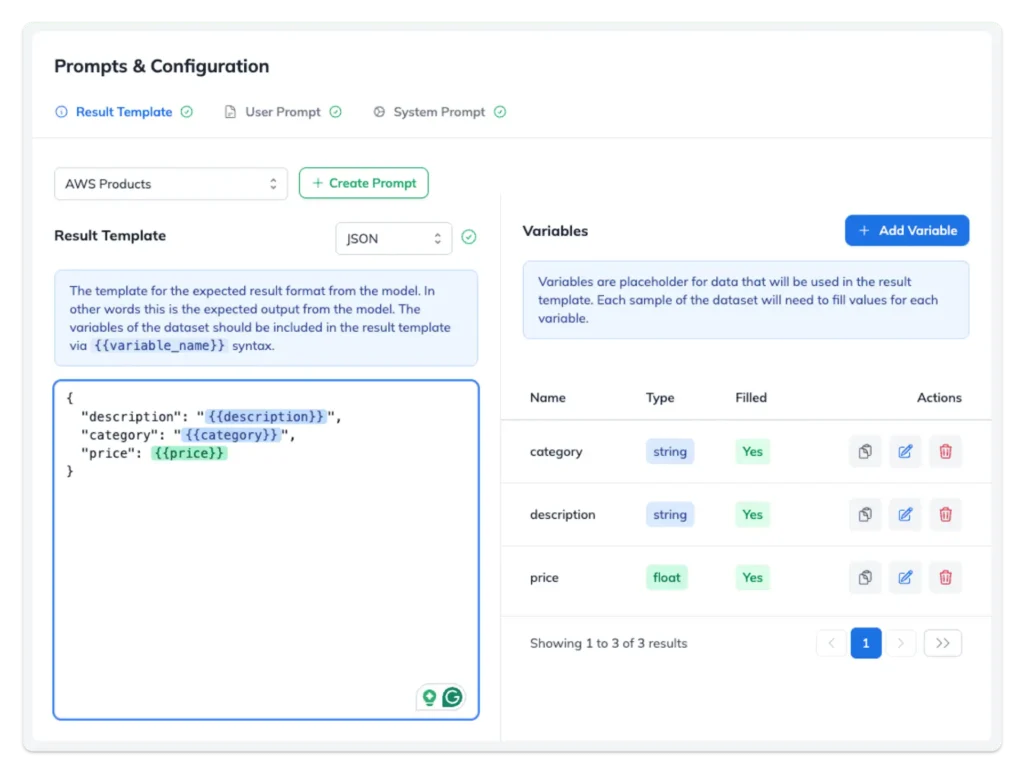
This approach helps VLMs stay consistent across thousands of samples. You define the output structure once, and every training example follows the same pattern. No manual JSON editing, no inconsistent formatting. This is how models learn to produce clean, predictable results every time.
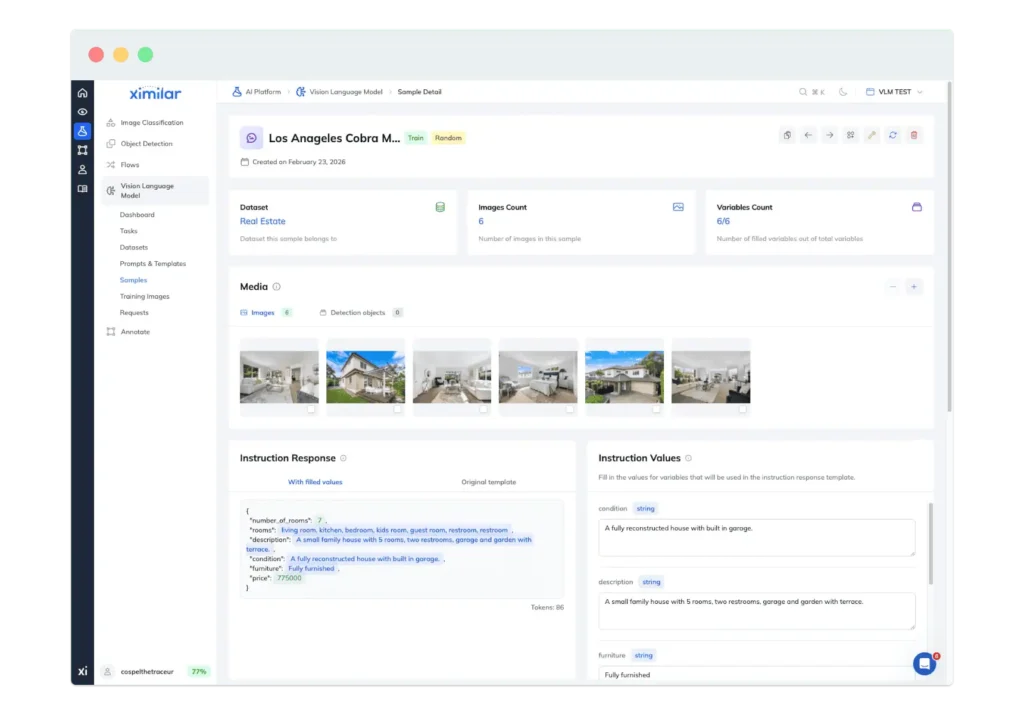
Samples
A Sample is a single training example within a Dataset. Each one consists of an image (or multiple images) paired with values for the variables defined in your result template. For example, if your result template includes {{brand}} and {{category}}, a sample might assign “Nike” and “Running Shoes.”
The platform’s UI makes this straightforward. You see your variables listed as form fields, fill them in, and move on to the next sample. You can manage hundreds or thousands of samples through the dashboard, or upload them programmatically via the API when working at scale.
Sample quality is the most important factor affecting performance. The model learns to produce consistent outputs based on how clearly and reliably these examples are structured.
This layered structure – Task → Dataset → Samples with templated variables – keeps your training data clean and consistent. It also makes iteration easy. You can, for instance:
- Swap out a Dataset to test a different output format.
- Adjust your system prompt to change the model’s behaviour.
- Add new variables to capture additional information.
The platform manages the full lifecycle, including evaluation metrics and performance tracking, so you can monitor how improvements in your data translate into better results.
Supported Open-Source Vision Language Models
When configuring a task, you can choose from several open-source models. We support both LoRA (Low-Rank Adaptation) and full fine-tuning across different model sizes and architectures. These are popular machine learning models for fine-tuning vision language tasks:
- Liquid Foundation Models (LFM2-VL and LFM2.5-VL) – The LFM2-VL-450M is our default and most cost-effective option – a model using minimal resources to deliver strong results. It is a compact model that uses a Siglip2 NaFlex image module combined with the LF2M transformer, delivering impressive vision capabilities. Ideal for edge deployment and a wide range of vision tasks. For Liquid Foundation models, companies exceeding $10M revenue need a commercial license from Liquid AI.
- Gemma 3 4B – A strong mid-range model with support for over 140 languages. Gemma 3 4B is a model that uses a Siglip image module paired with a Gemma 3 transformer architecture. It offers an excellent balance between model performance and resource efficiency. Make sure to review Google’s terms before production use.
- Qwen3-VL – Alibaba’s latest multimodal model series, available in dense variants. Qwen3-VL uses a DeepStack ViT module with an Interleaved-MRoPE transformer and supports advanced spatial and video understanding. Assessing VLMs like Qwen3-VL on standard benchmarks consistently places it among the top open-source VLMs.
| Model Version | License | Languages | Context Window | Sizes | GPU Req. | Architecture | More Info |
| LF2-VL | License | en, ja, ar, zh, fr, de, ko, es, pt | 32K | 450M and 1.6B | ~4GB | Siglip2 NaFlex + LF2M transformer | Official post |
| Gemma 3 | Terms and Use | over 140 languages | 128K | 4B | ~7GB | Siglip + Gemma 3 transformer | Official post, Developers |
| Qwen3-VL | Apache 2.0 | multilingual, 32 OCR languages | 256K | 2B, 4B | ~7GB | DeepStack ViT + Interleaved-MRoPE | GitHub |
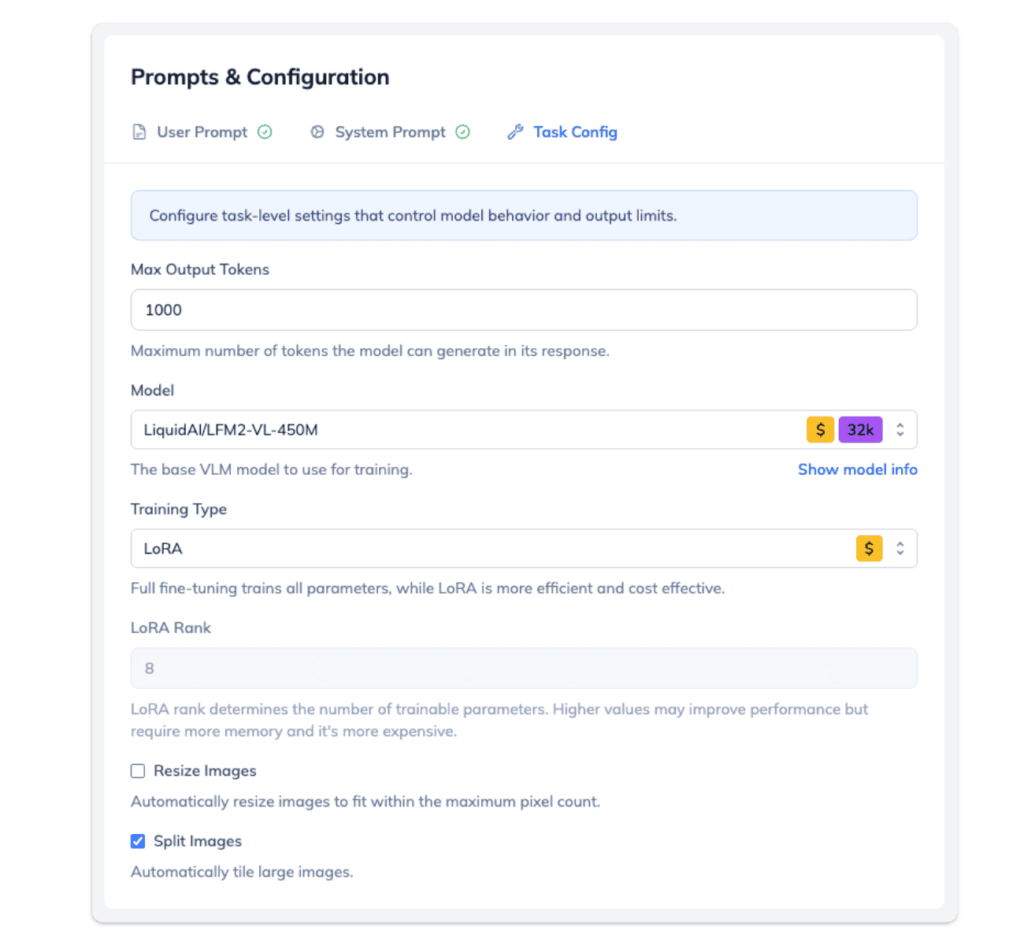
LoRA vs Full Fine-Tuning
We support two training approaches:
- LoRA (Low-Rank Adaptation) trains only a small fraction of the model’s parameters. It is the right choice for most use cases. It is faster, cheaper, uses less memory, and also enables the model to preserve its general reasoning capabilities while adapting to your domain – the model also retains broader language understanding this way.
- Full fine-tuning trains all parameters for maximum accuracy. It is slower and more resource-intensive, but captures deeper domain knowledge. Use it when you have a large, diverse training dataset and need the highest possible model performance on your VLM tasks.
Vision Language Model Privacy & Ownership
Privacy-First Architecture
Our approach is privacy-first. Your training data stays on Ximilar’s infrastructure during training and is never shared with third parties or used to improve other models. If you download your model and run it offline, your inference data never leaves your control either.
This is fundamentally different from sending every request to OpenAI or Google, where your inputs can feed into their systems. For GDPR compliance, data sovereignty requirements, or any scenario where sensitive data cannot leave your premises, fine-tuning local vision language models is the only viable path.
You Own Your Model
You have full ownership of all vision language models built on our platform. Download your VLM in a portable format and run it on any compatible runtime, with no vendor lock-in. The base VLMs (LFM2, Gemma, Qwen3-VL) are open-source, so you must respect their respective licences, but your trained version is yours to use, modify, and deploy however you see fit.
With a smaller model running on a consumer-grade GPU, you get faster inference and predictable, fixed-cost deployment. Stop paying per token – start owning your models. If you decide to leave Ximilar tomorrow, your model comes with you.
Inference: On-Device or Via API
Once your vision language model is trained, you have two deployment paths.
Deploy Offline: Private, Fast, Predictable Costs
Export your fine-tuned VLM and deploy it on your own hardware – a laptop, an on-premise server, an edge device, or a cloud VM you control. Your model and your infrastructure mean zero dependency on Ximilar or any other provider after download.
The cost difference between these deployment approaches and generic cloud APIs is significant. A fine-tuned Gemma 3 4B or Qwen3-VL 2B running on your own GPU incurs no per-token fees whatsoever. OpenAI’s GPT-4 Vision charges $0.01–$0.03 per image.
At a few thousand requests per day, that is the difference between a flat hardware cost and an API bill that grows with every user. For high-volume applications, fine-tuning reduces inference costs by 80–95%. The advantages over calling a cloud API are fundamental, not incremental. We will cover the technical details of offline deployment in a dedicated follow-up article.
Connect Via REST API
Start making predictions immediately. Send an image and a prompt to your model’s endpoint and receive a structured response. No infrastructure to manage.
This works well for web applications, mobile backends, and any system capable of making HTTP calls.
Our 2026 Roadmap
Here is what we are building next:
- Automatic post training quantization – quantize your fine-tuned VLM and deploy it efficiently on edge devices, laptops, and smartphones.
- Function and tool calling – enabling fine-tuned VLMs to call external tools and APIs, making small autonomous agents possible, with optimisation for edge devices and CPU-only deployment.
- Video and audio fine-tuning – extending the platform beyond images to additional modalities, along with smoother dataset management for larger, more complex training sets.
- RAG-based systems – several customers have requested retrieval-augmented generation (RAG) built on their fine-tuned VLMs. We have started experimenting with this and plan to ship it as a platform feature.
- More open-source model integrations – the vision-language model landscape is moving fast, and we plan to integrate new models, that can run on consumer hardware as they emerge.
We hope this platform helps individuals, communities, and companies create amazing solutions. If you would like to discuss your use case or need help getting started, feel free to contact us.

Tags & Themes
Related Articles
The New Ximilar Interface: Overview and Key Changes
Discover the redesigned Ximilar App – a clearer, faster way to train models, manage credits, and explore visual AI solutions.
Recognize New & Rare Cards With AI Sports Card Identification
With millions of cards and variations, even the best databases miss some. We refined our sports cards recognition to identify cards even when no match exists.

Final Fantasy, Sorcery, Gundam & Riftbound Added to Our Recognition System
Ximilar’s trading card game recognition system now supports Final Fantasy, Sorcery: Contested Realm, Gundam, and Riftbound. Let’s see it in action!